Minería de Datos: Preprocesamiento y clasificación
Máster en Ciencias de Datos e Ingeniería de Computadores
Ecosistema de visualización en R
Ecosistema de visualización en R
ggplot2 es con diferencia el elemento de R mejor valorado para Ciencias de Datos.
Tiene una filosofía muy diferente de otros entornos, está basado en Grammar of graphics o Gramática de gráficos. Consiste en crear los gráficos por capas que se unen. Es muy fácil de usar pero al mismo tiempo muy personalizable.
Vamos a ver sólo un poco como usarlo con ejemplos, no todas las opciones posibles, existen otros tutoriales recomendables1.
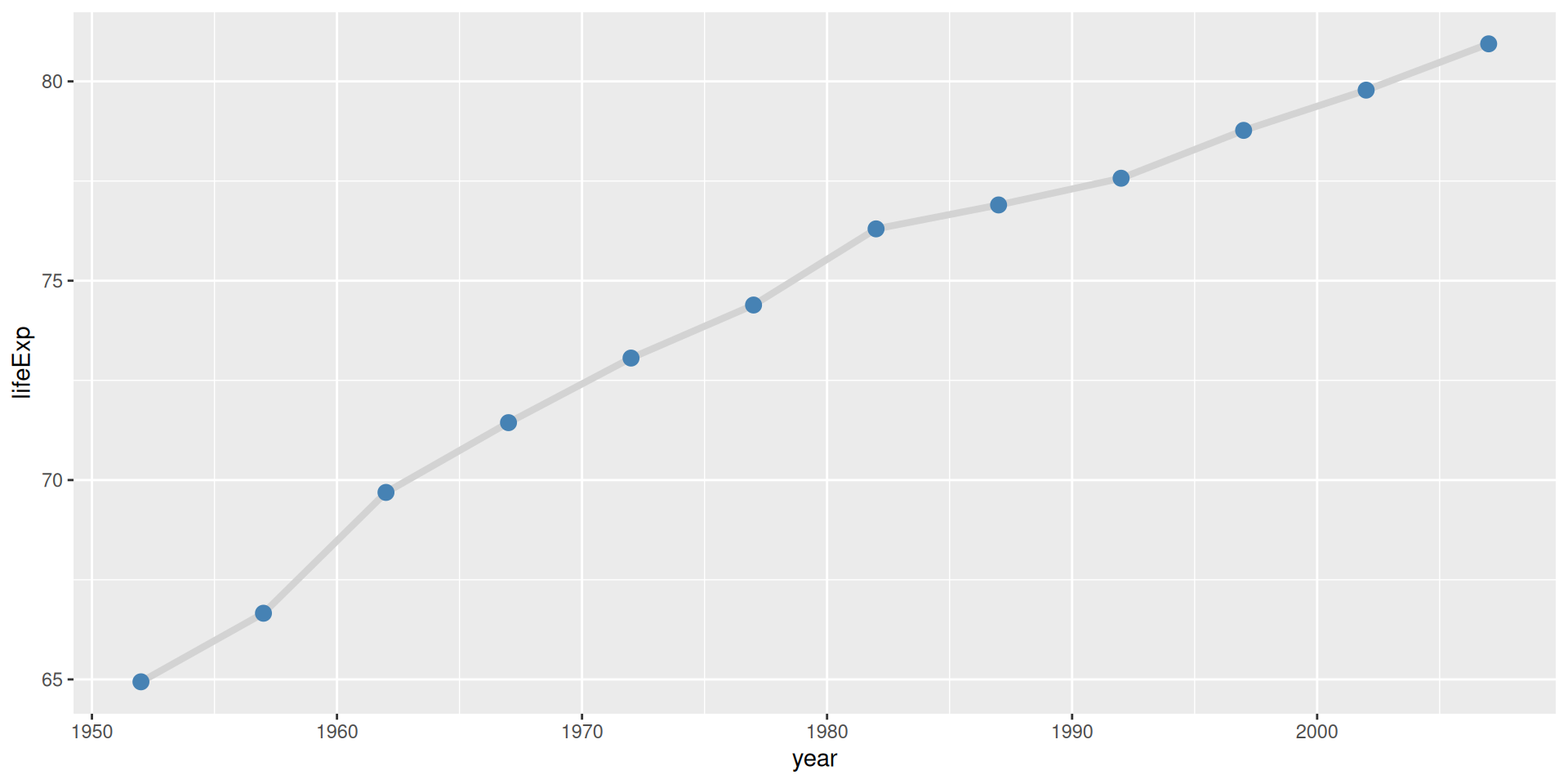
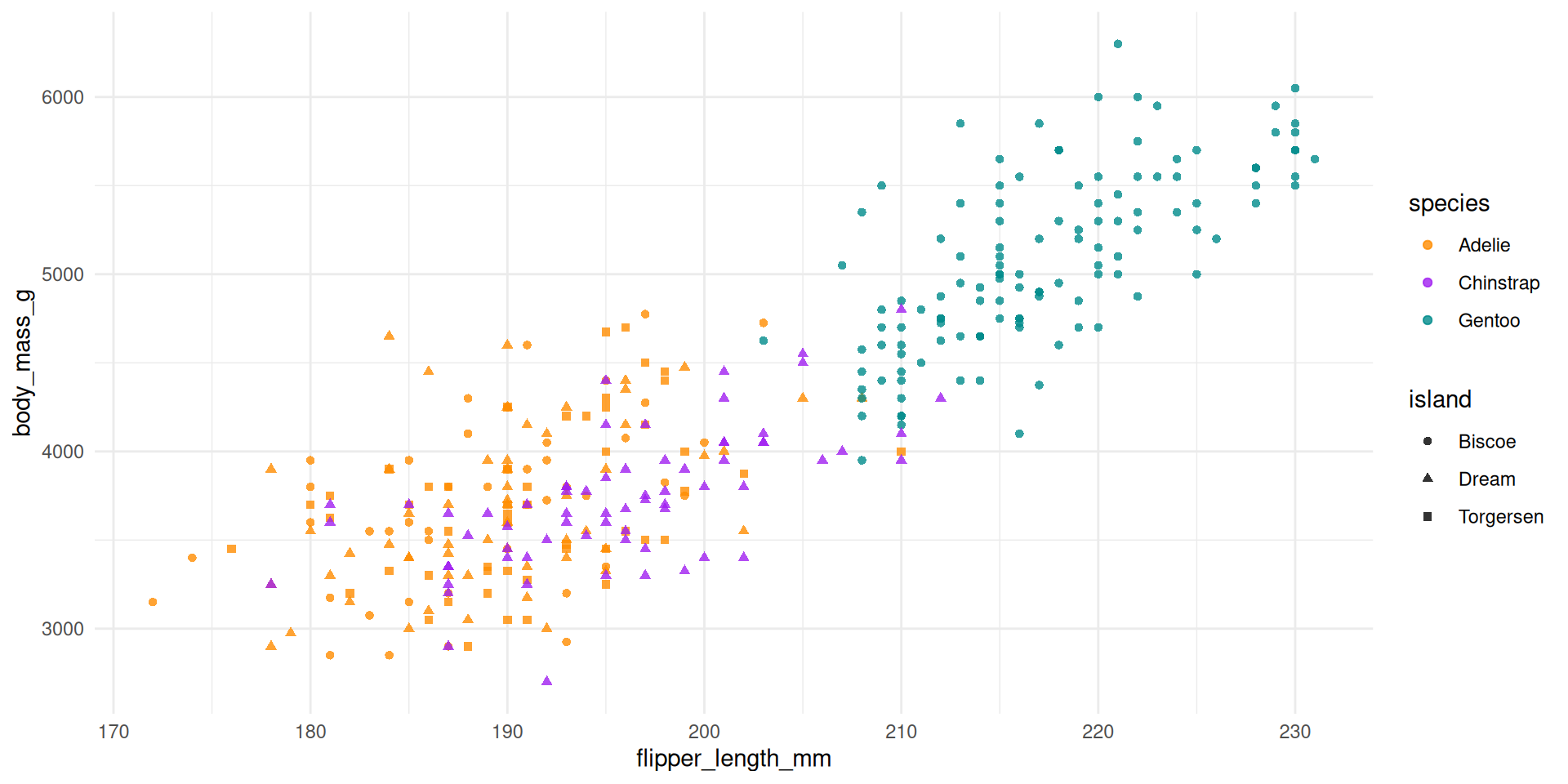
Cargamos unos datos de ejemplo
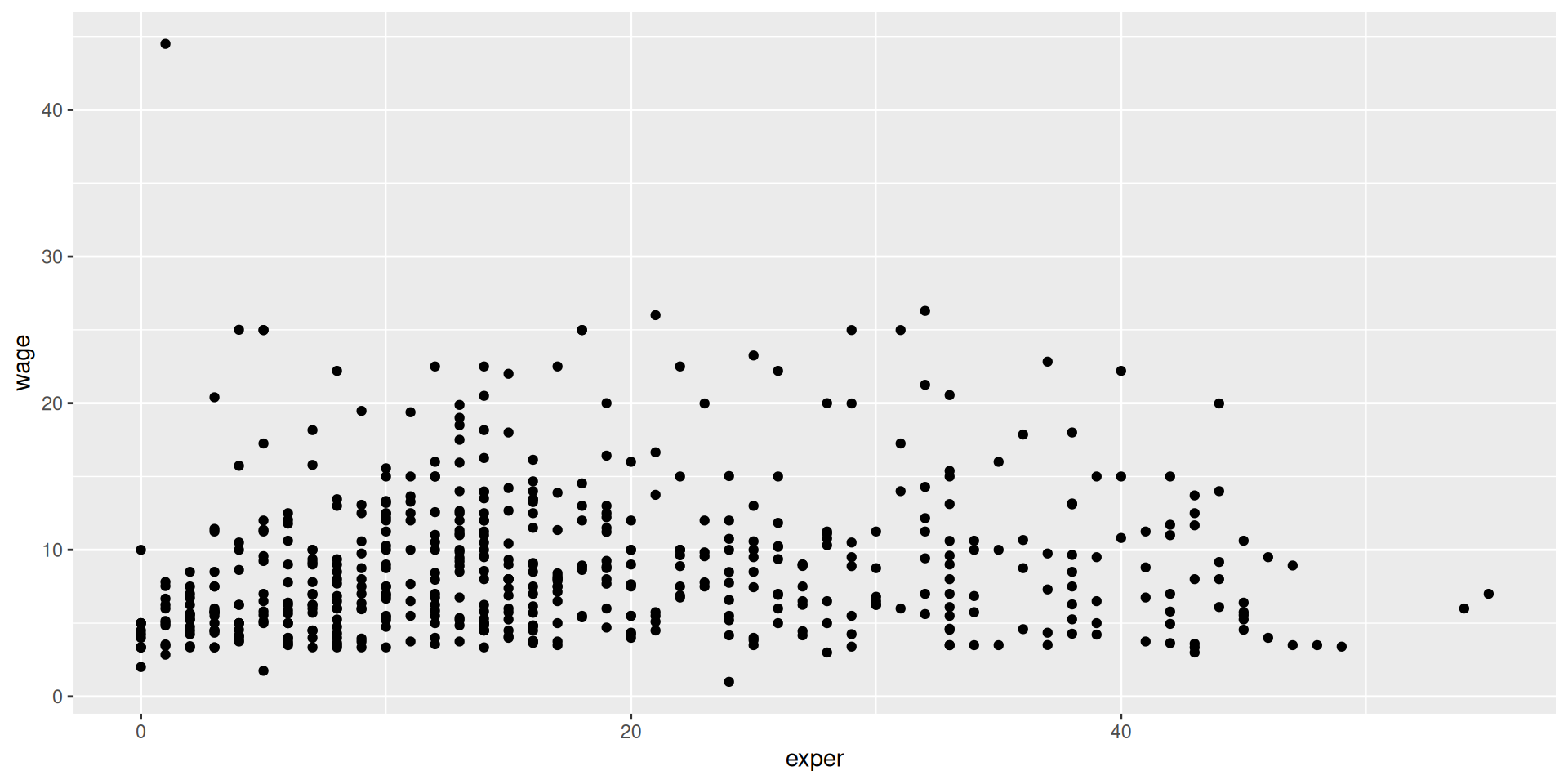
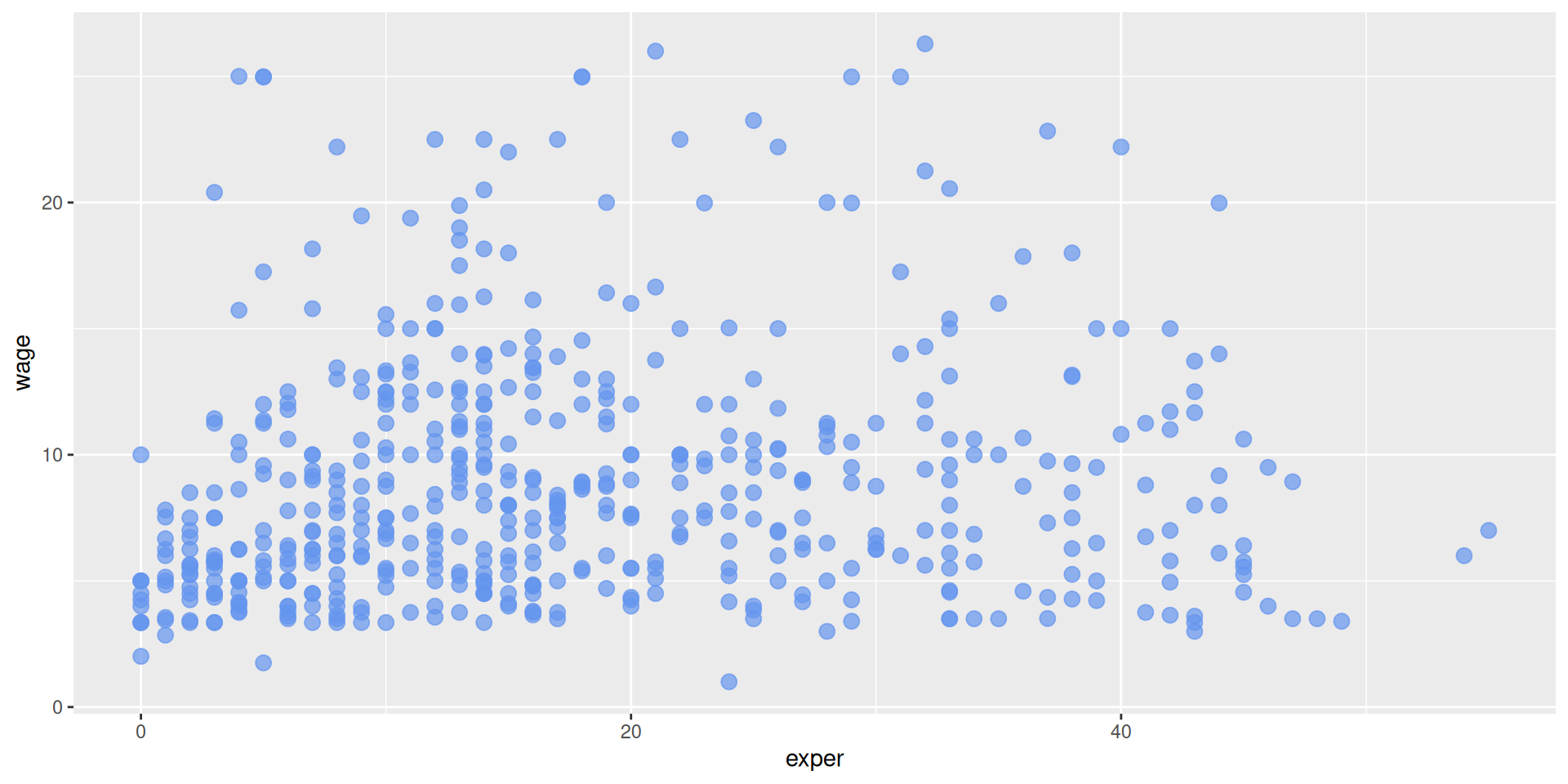
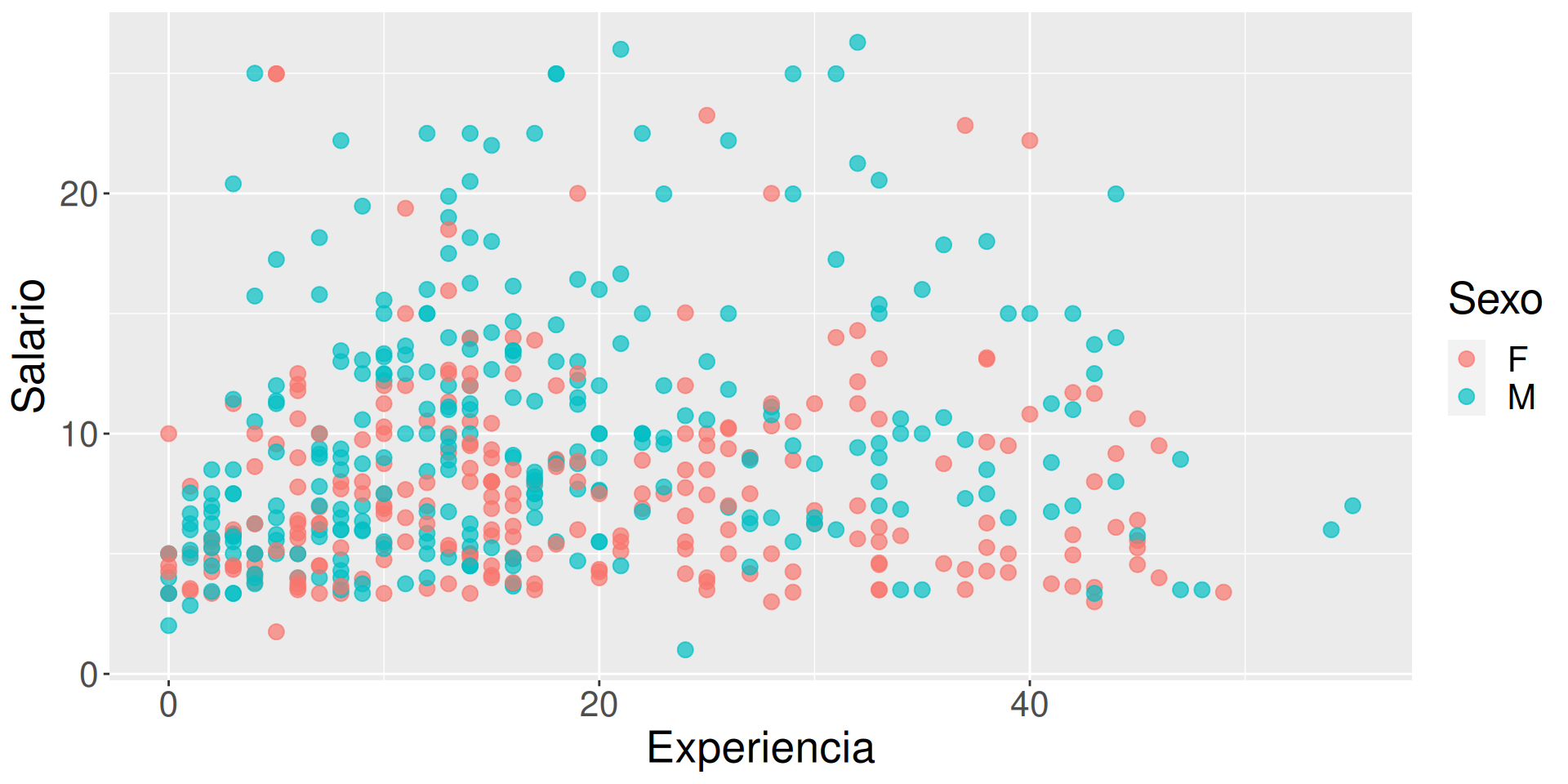
Vamos a cargar unos datos de sueldos.
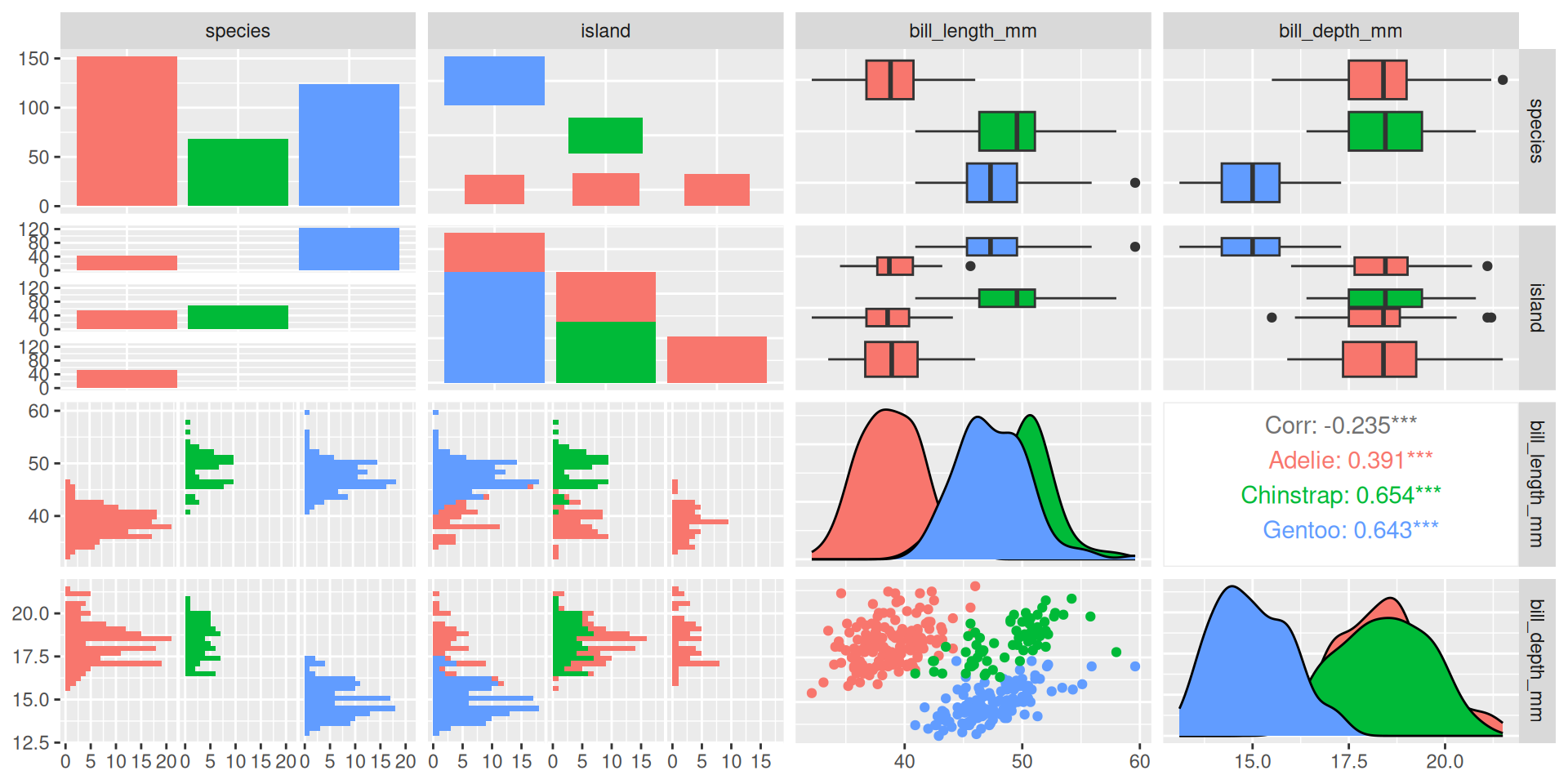
list.of.packages <-c("ggplot2", "mosaicData", "dplyr", "treemapify", "GGally", "carData", "ggthemes", "ggridges", "gapminder", "palmerpenguins", "ggcorrplot")new.packages <- list.of.packages[!(list.of.packages %in%installed.packages()[,"Package"])]if(length(new.packages)>0) install.packages(new.packages, repos="https://cloud.r-project.org/")library(ggplot2)library(mosaicData)library(dplyr)# se cargan los datos del paquete mosaicData: incluye# datos obtenidos para estudiar las relaciones entre# salarios y experiencia laboraldf <-data(CPS85 , package ="mosaicData")df <- CPS85colnames(df)
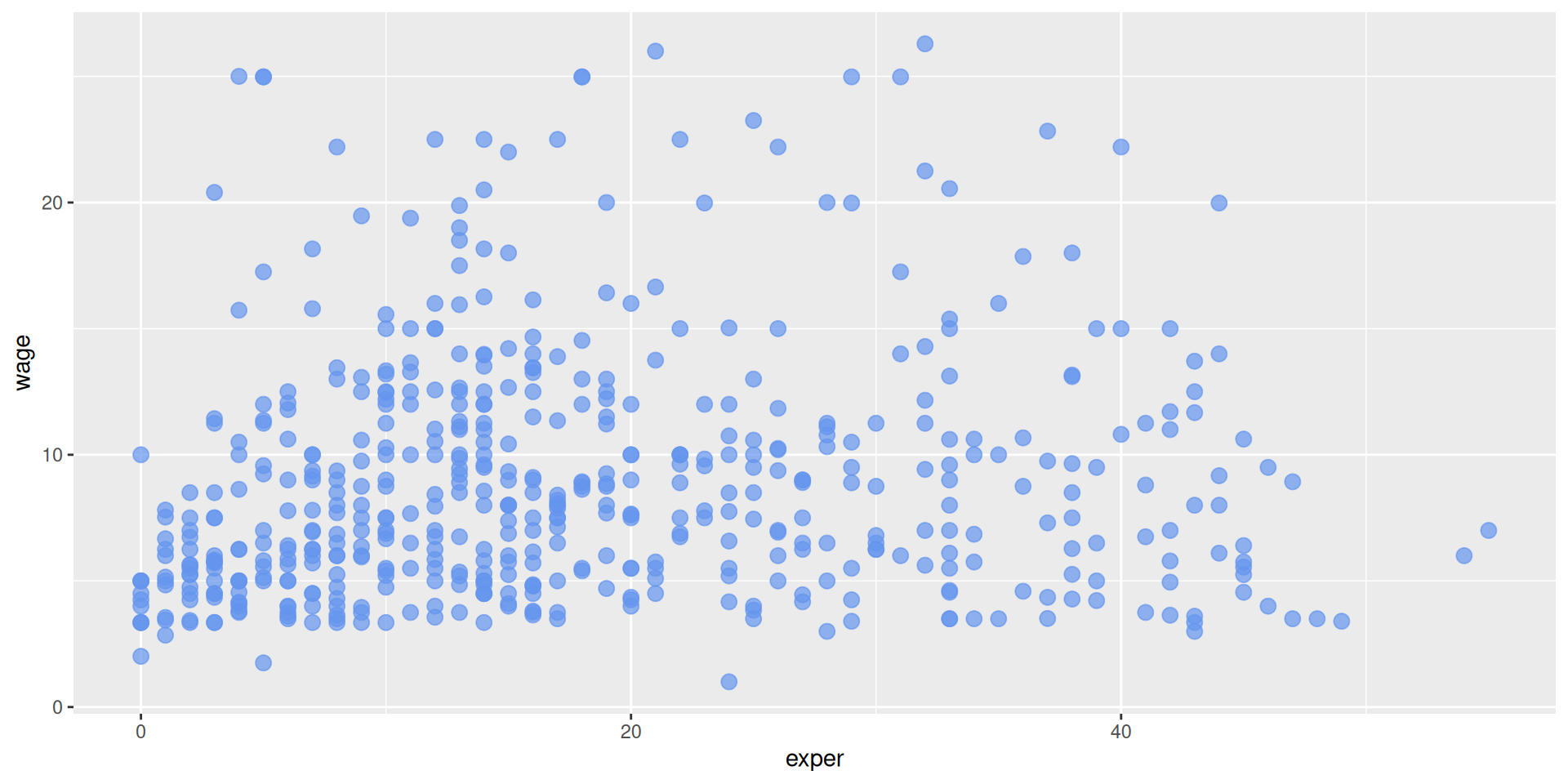
Muy feo, podemos poner opciones a visualizar dentro de geom_point, como el color (negro por defecto), si usar transparencias (por defecto es opaco), o el tamaño del punto (sobre el de referencia, > 1 lo aumenta).
Para mostrar luego basta con añadir una línea con g (en Notebook).
A partir de ahora lo usamos combinando más capas.
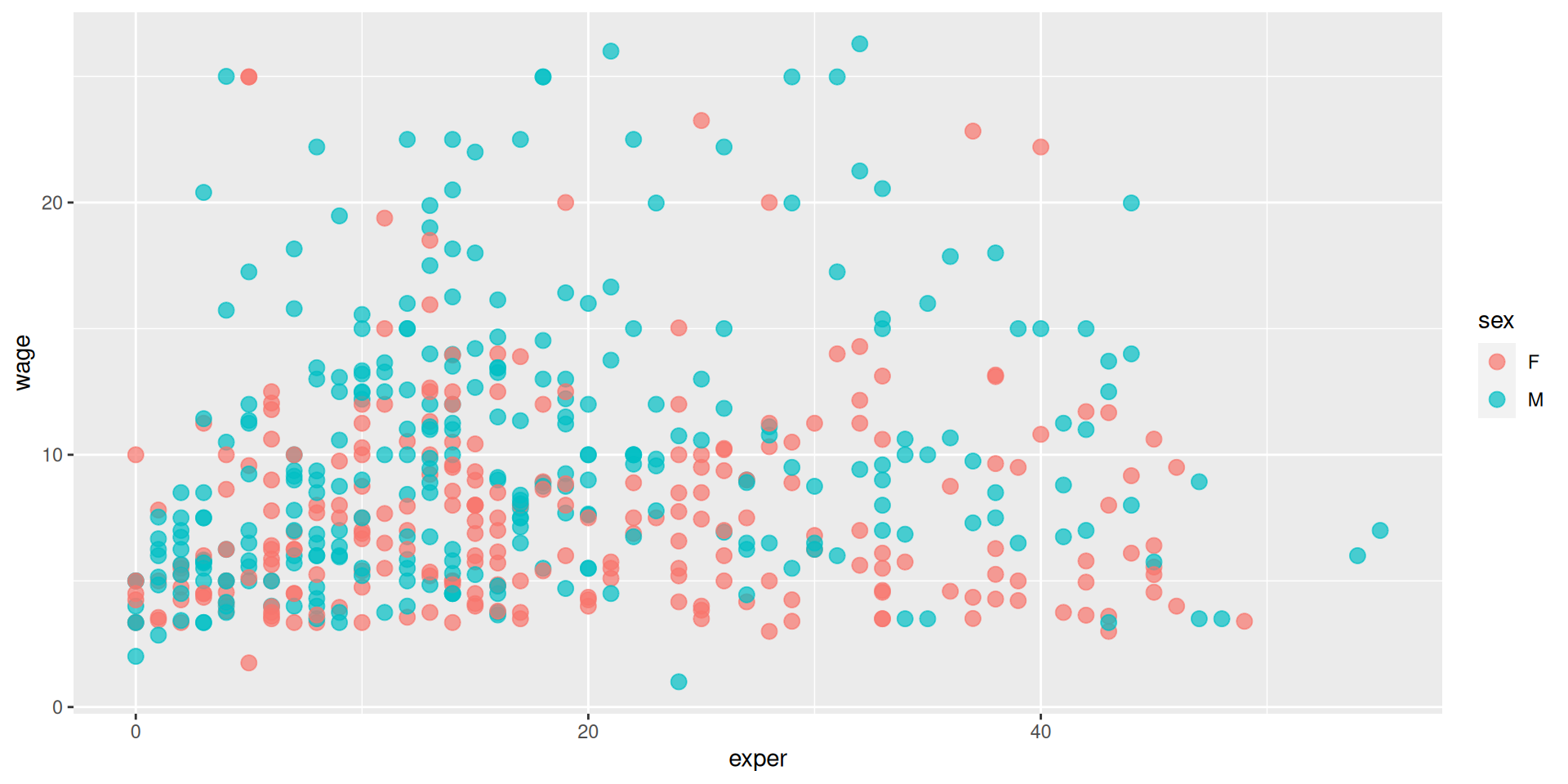
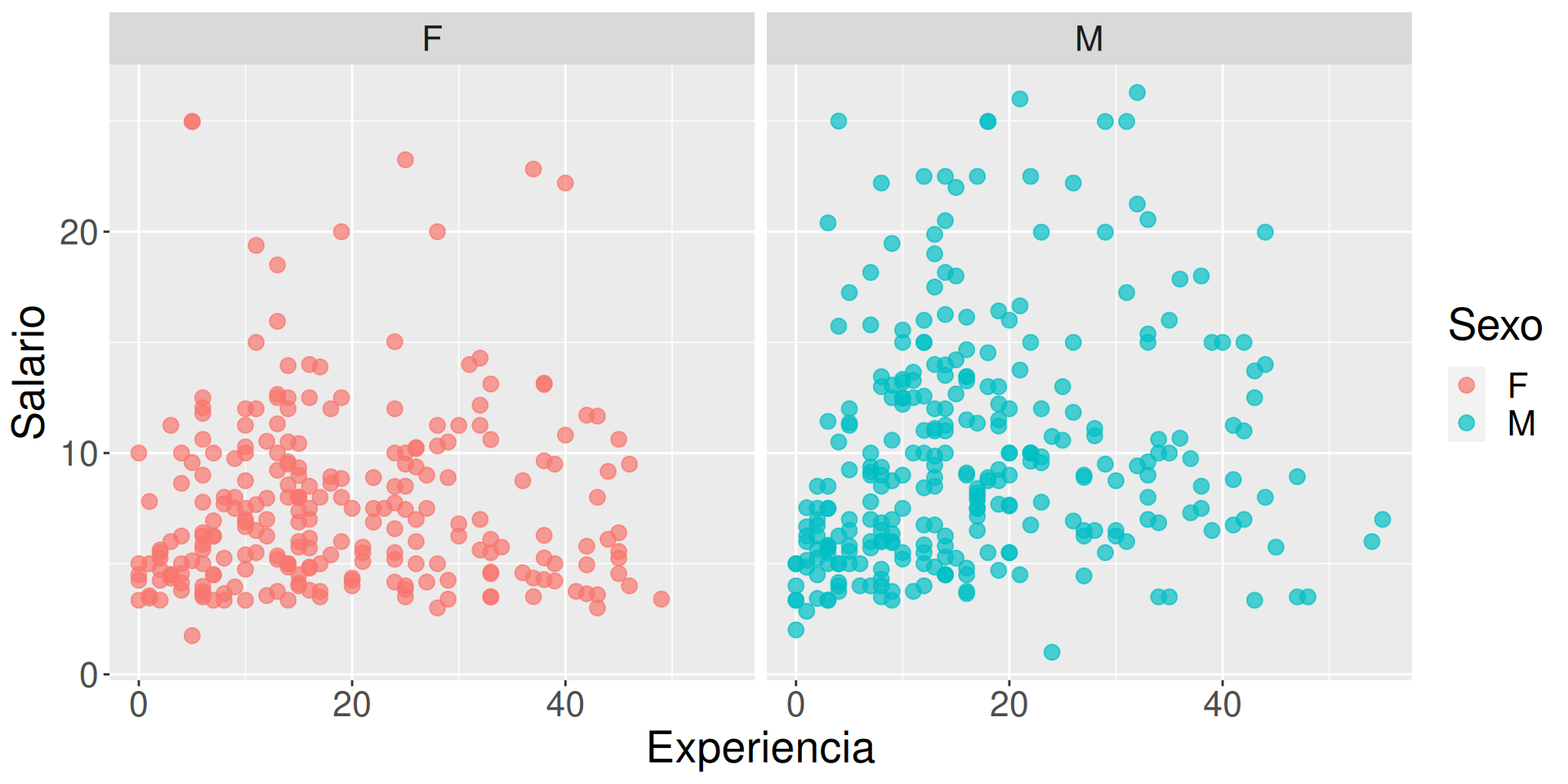
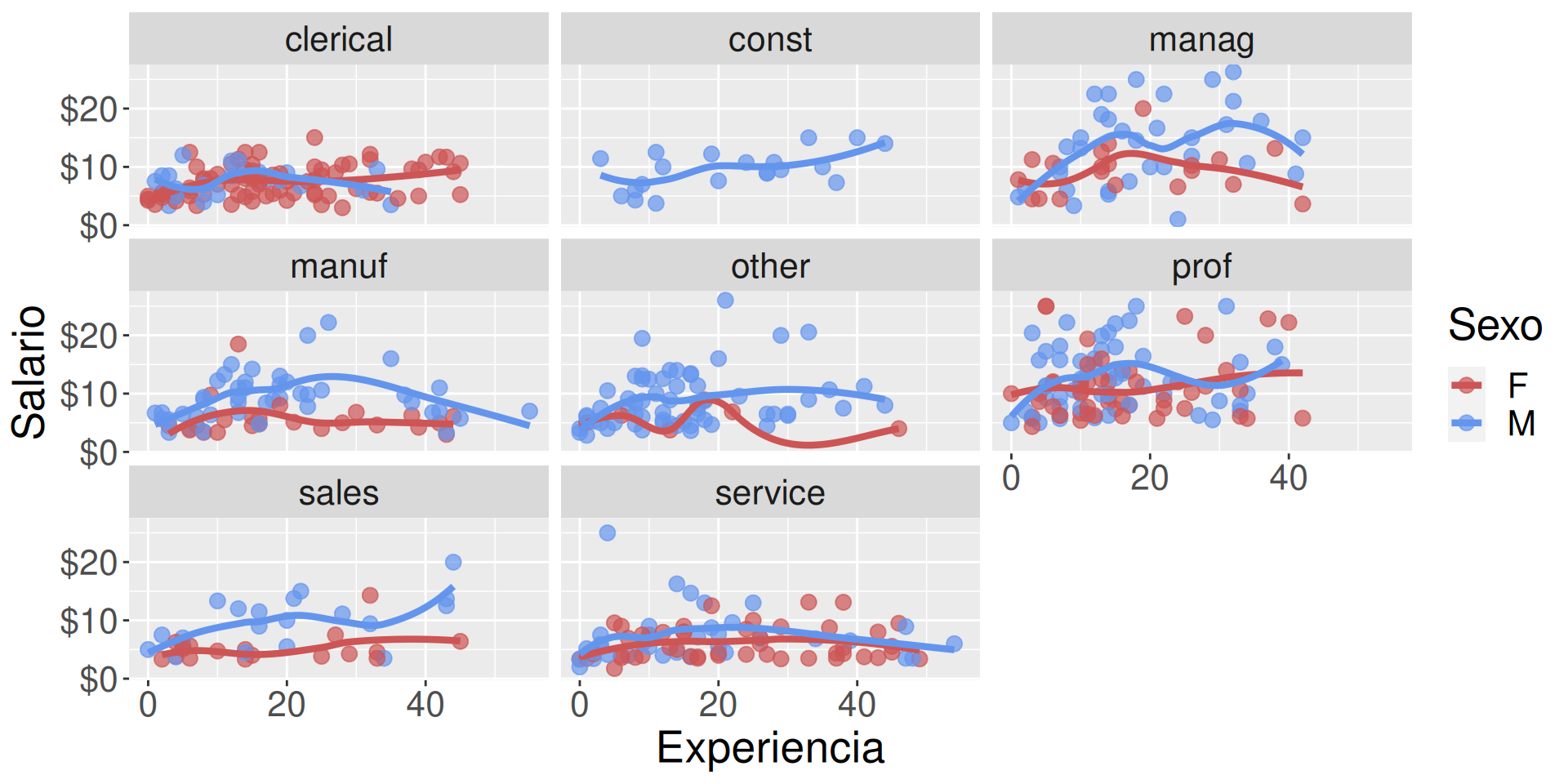
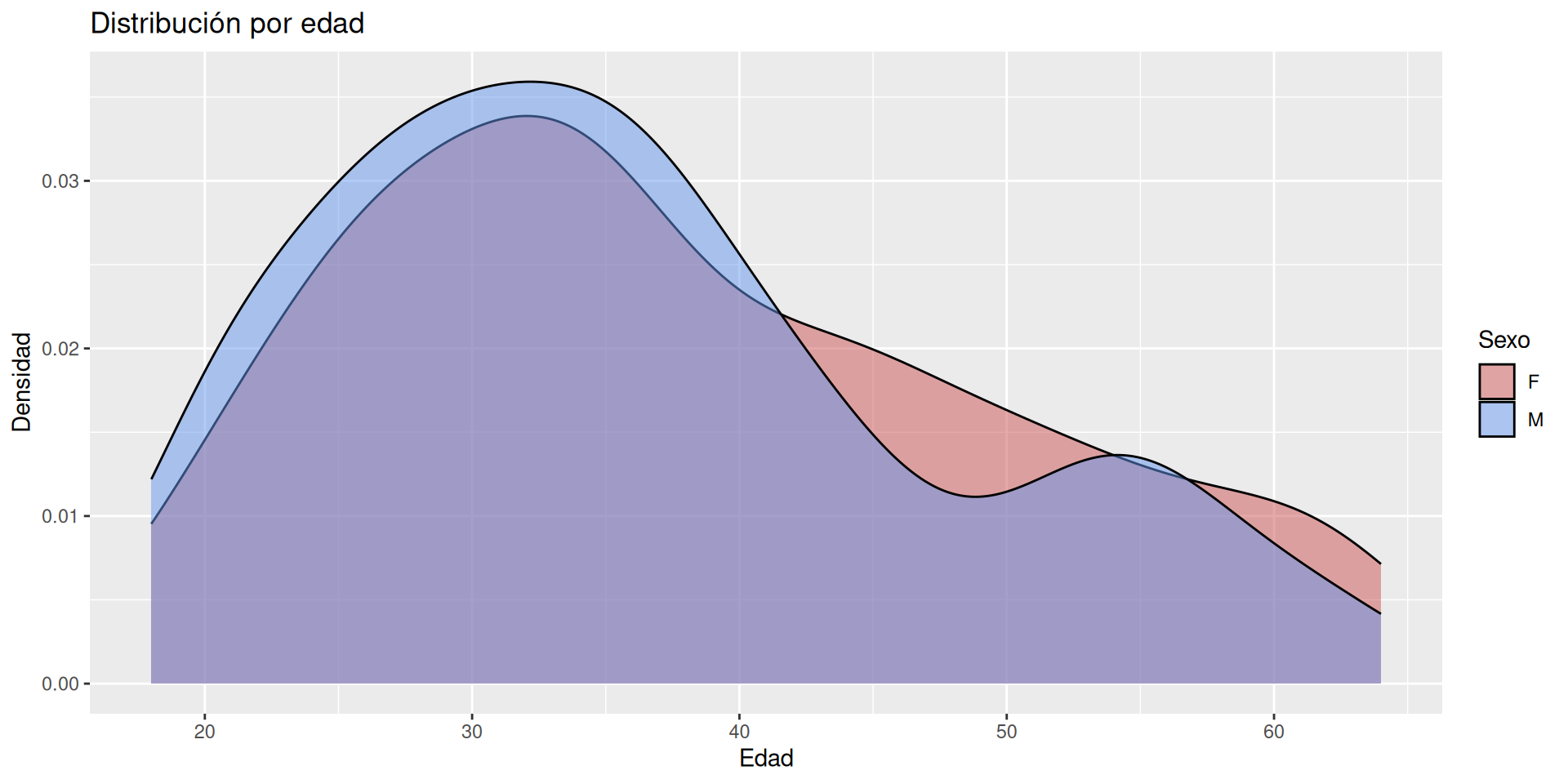
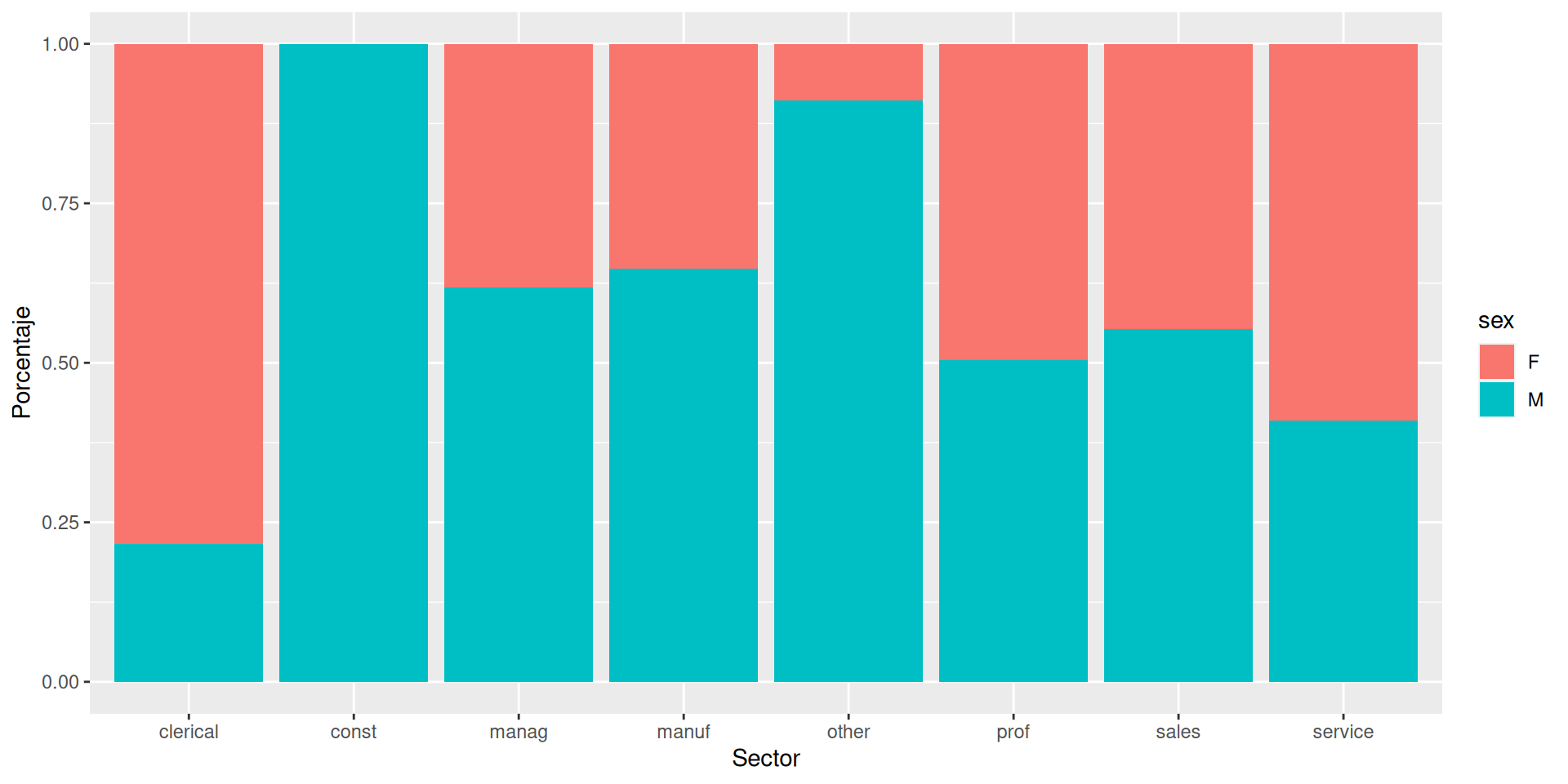
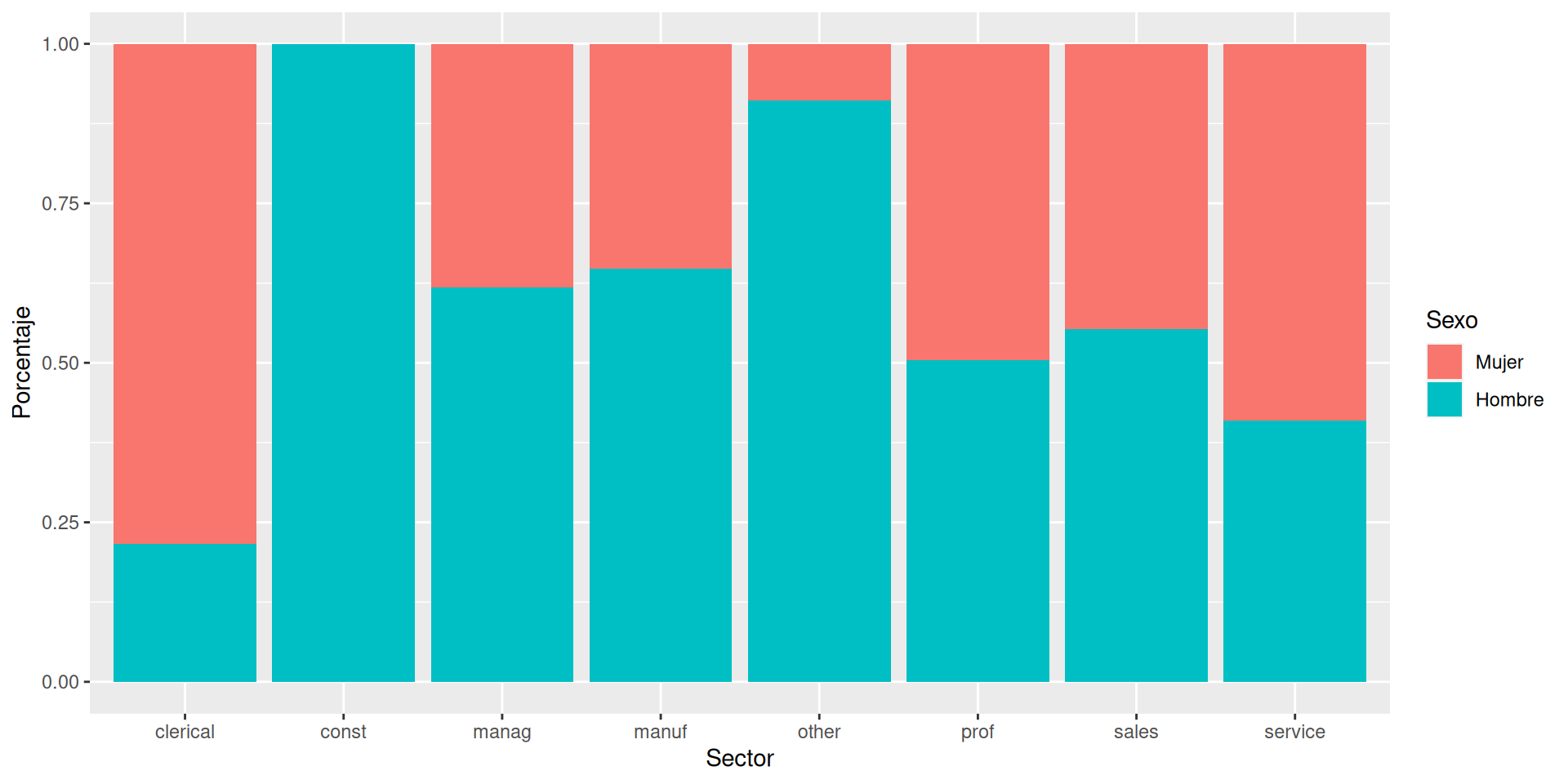
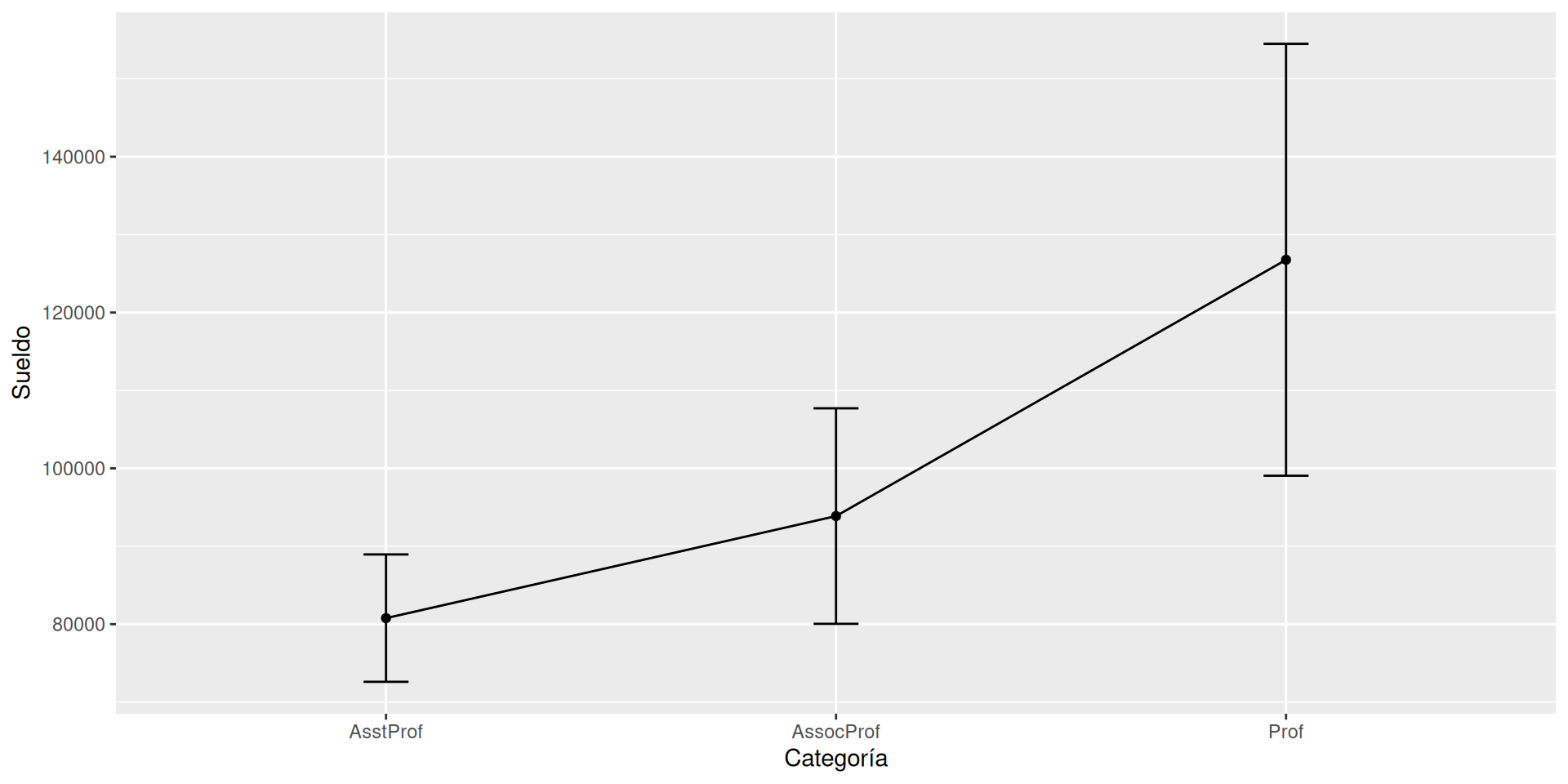
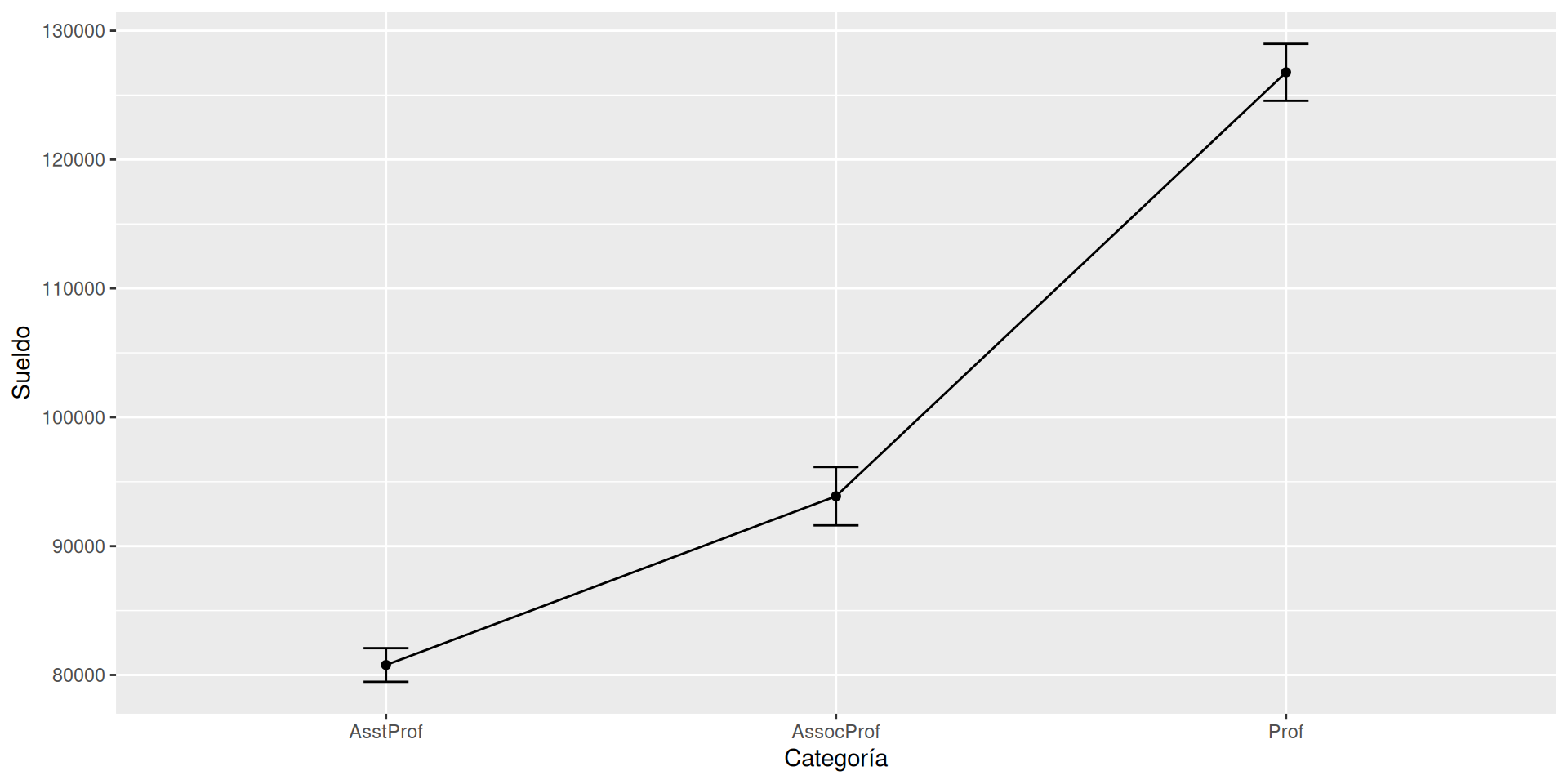
Distinguiendo sexo por separado
Podemos añadir elementos para adaptar la figura. Usamos facet_wrap (o facet_grid) para separar por atributos.
g +facet_wrap(~sex)
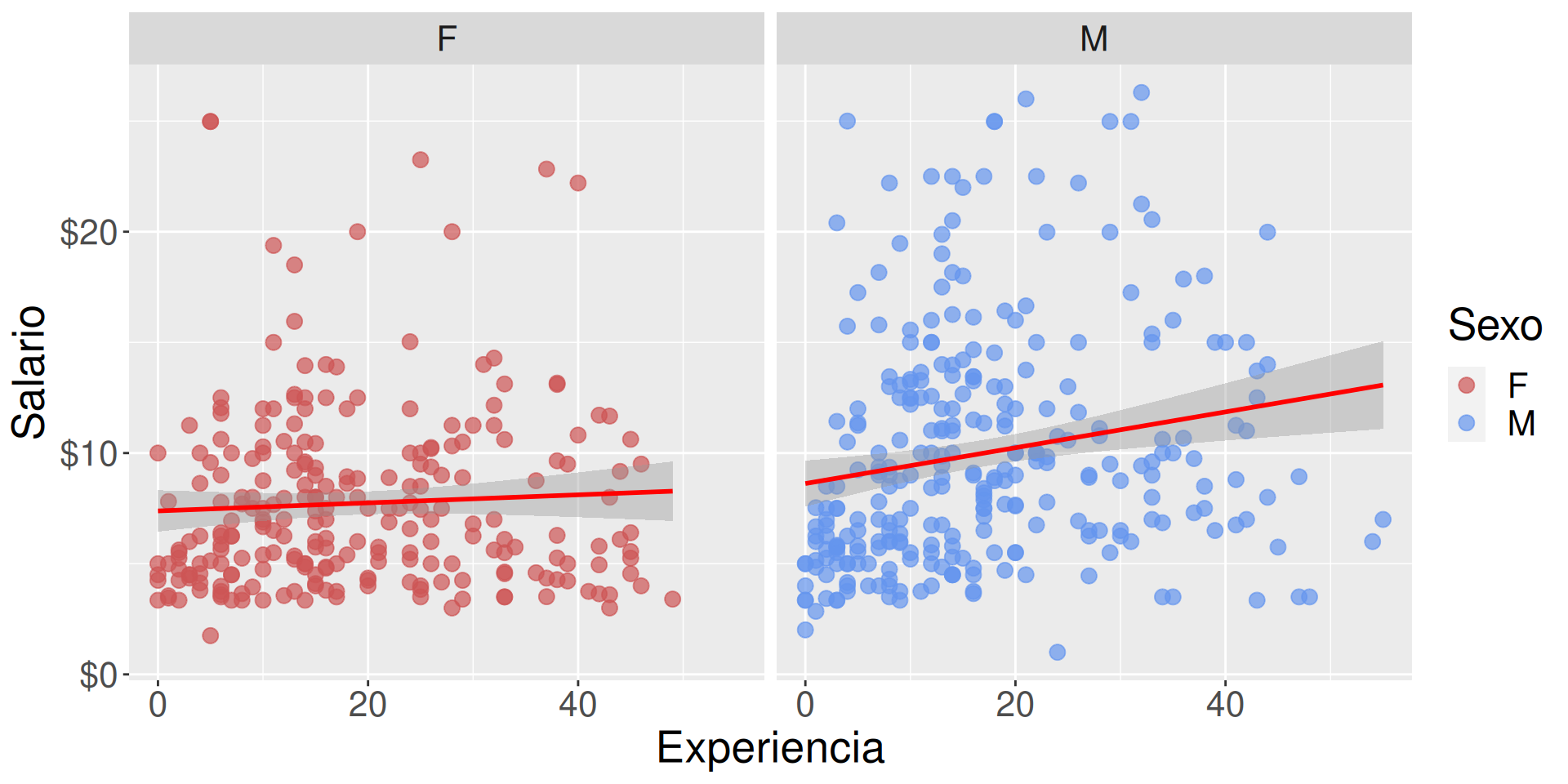
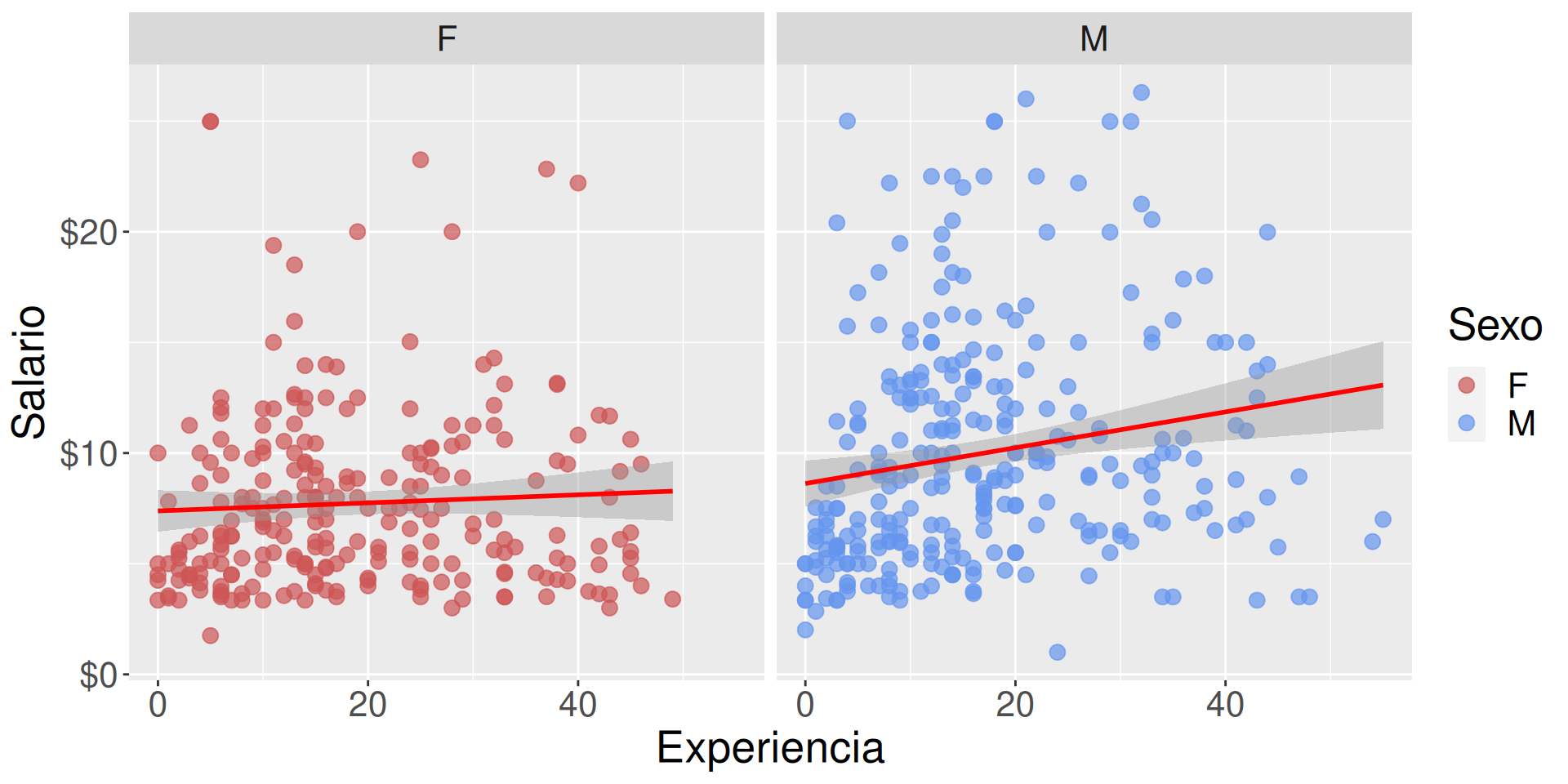
Ajuste de presentación
Usar una técnica que ajusta una serie de puntos, geom_smooth.
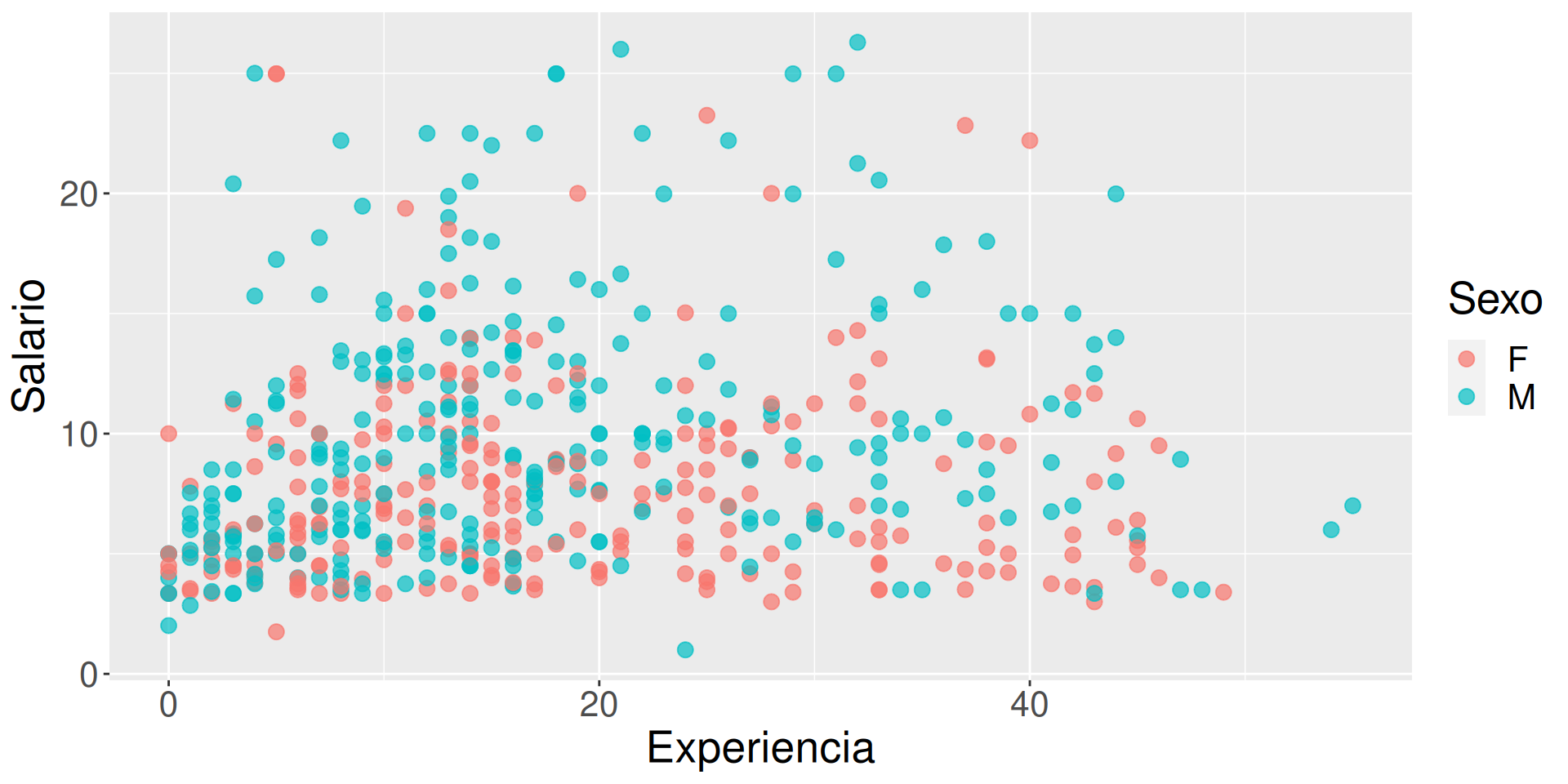
Los colores son feos, los ajustamos manualmente con scale_color_manual.
g +facet_wrap(~sex) +geom_smooth(method ="lm", formula=y ~ x, color="red") +scale_y_continuous(label = scales::dollar) +# Añadimos un $scale_color_manual(values =c("indianred3", "cornflowerblue"))
g2 <- g +facet_wrap(~sex) +geom_smooth(method ="lm", formula=y ~ x, color="red") +scale_y_continuous(label = scales::dollar) +# Añadimos un $scale_color_manual(values =c("indianred3", "cornflowerblue"))g2
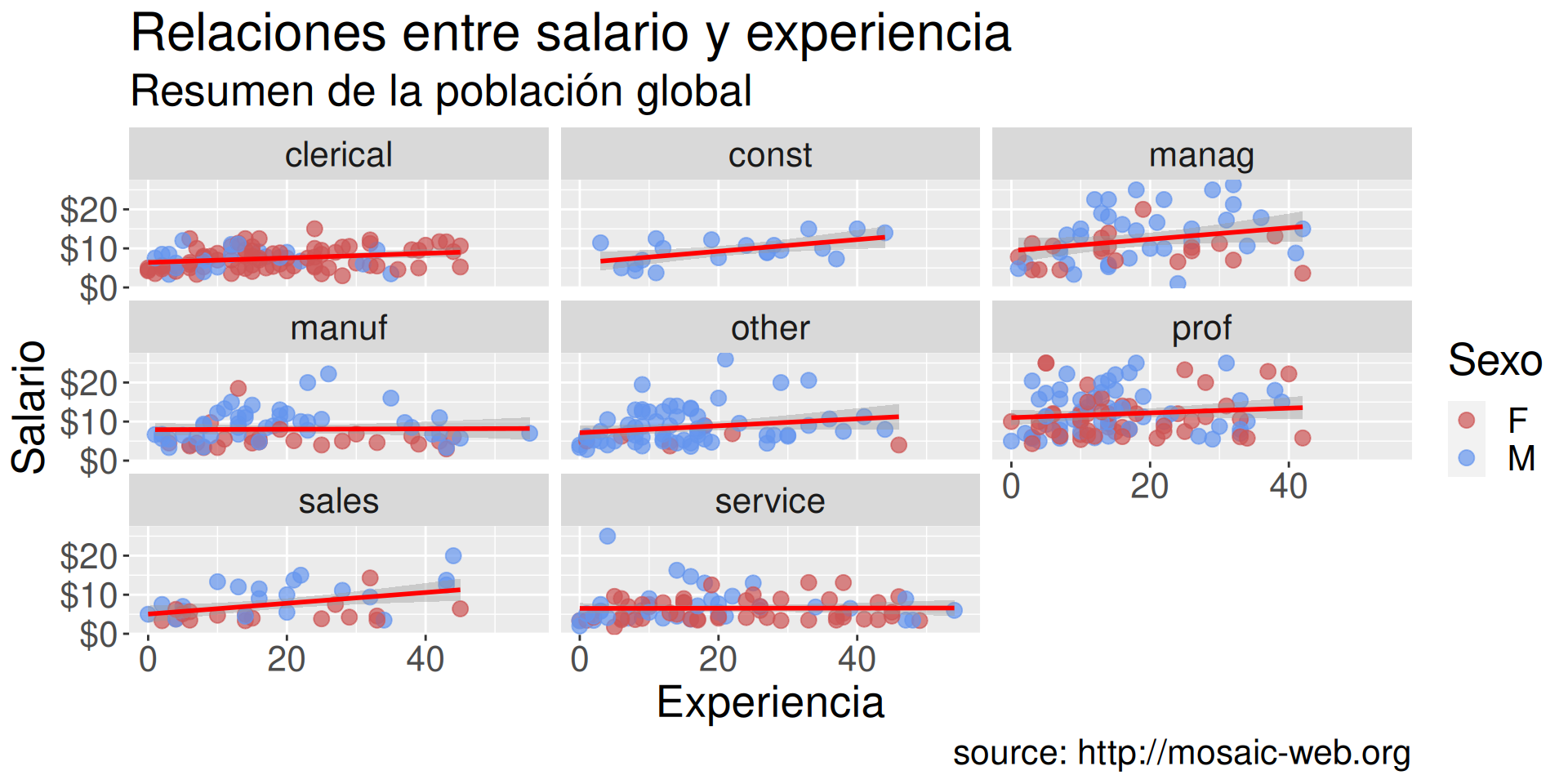
Uso combinado de facet para mejorar el sector
g +geom_smooth(method ="auto", se =FALSE, linewidth =1.5) +scale_y_continuous(label = scales::dollar) +scale_color_manual(values =c("indianred3","cornflowerblue")) +facet_wrap(~sector) # O g2+facet_wrap(~sector)
Mejorando la presentación
Mejorando la presentación
Ya hemos visto temas de presentación:
labs para indicar el tamaño.
cols, alpha en geom_XXXX para fijar un mismo color a toda la figura.
scale_color_manual para especificamos los colores cuando usamos color en aes.
Ahora vemos:
title y subtitle para el título.
caption para indicar información específica (fuente de los datos, …).
g2 +facet_wrap(~sector) +labs(title="Relaciones entre salario y experiencia", subtitle="Resumen de la población global", caption ="source: http://mosaic-web.org")
Tipos de Gráficos de una variable
Tipos de Gráficos de una variable
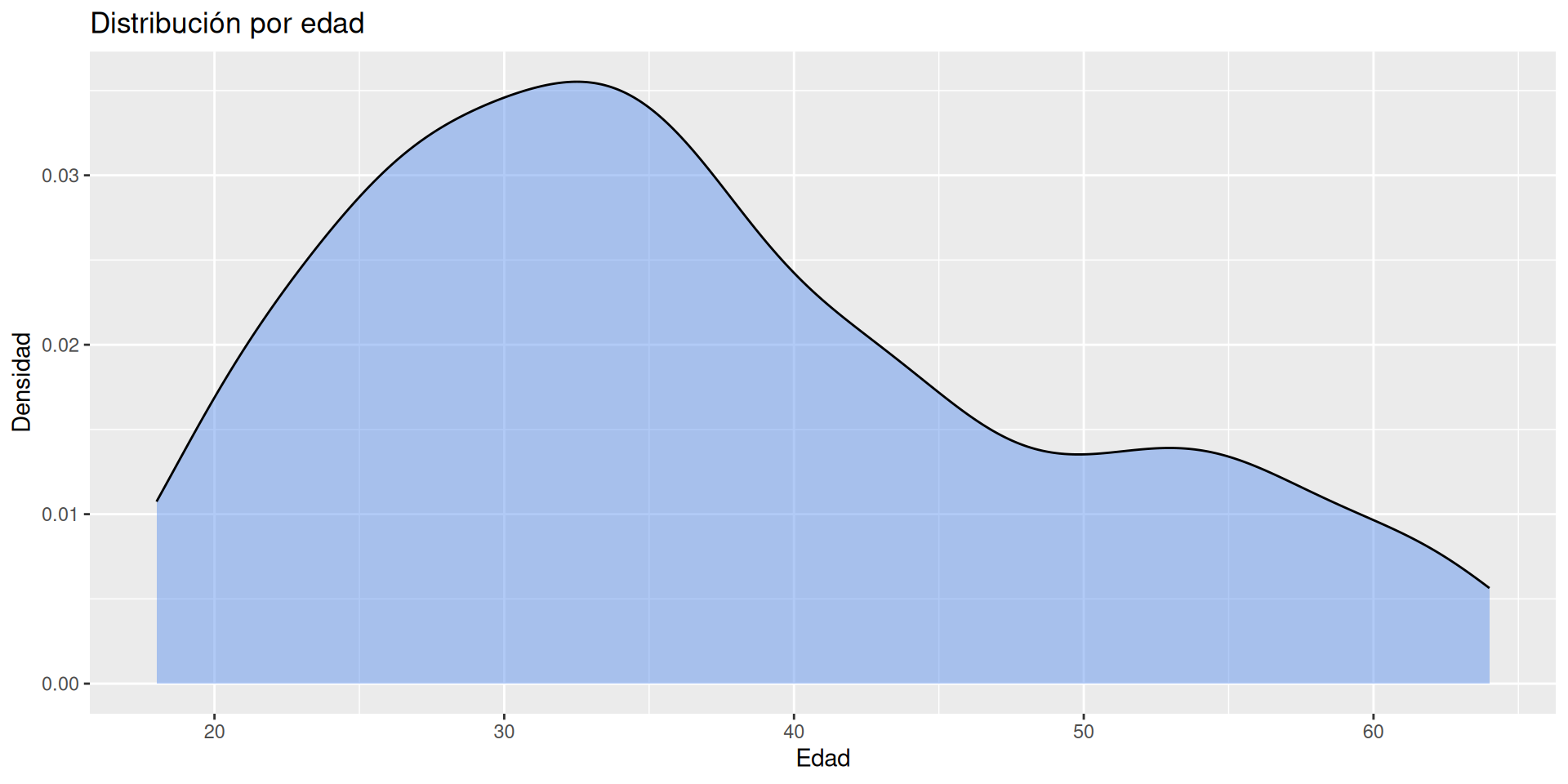
Son gráficos muestran la distribución de una variable, pueden ser categóricos o cuantitivas.
Categóricos: Se aplica diagrama de barras.
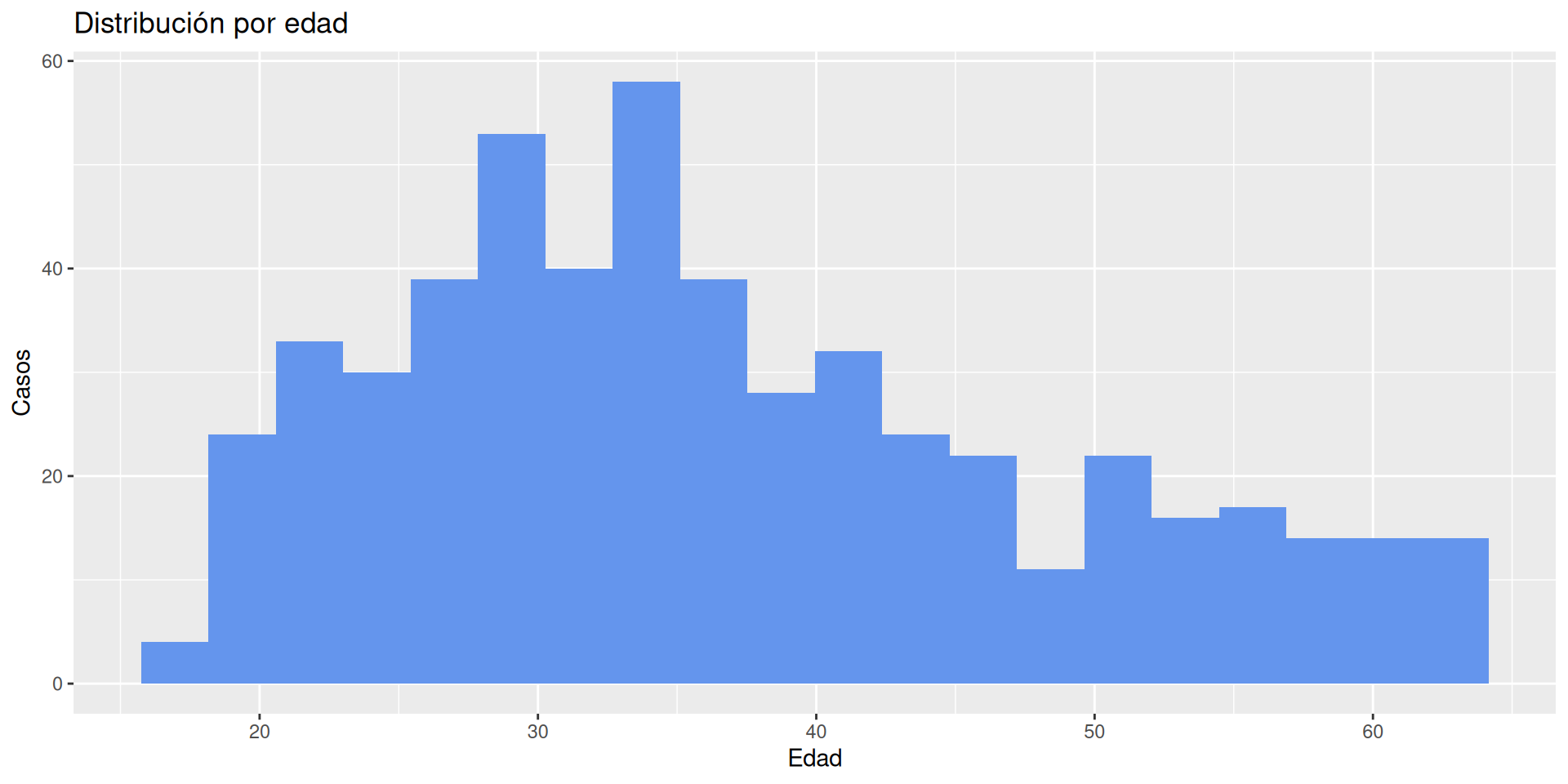
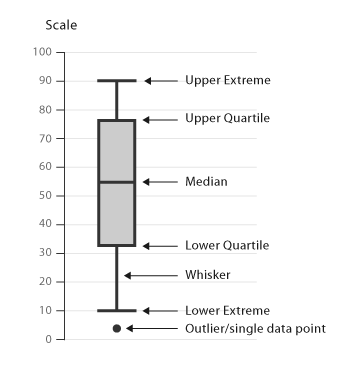
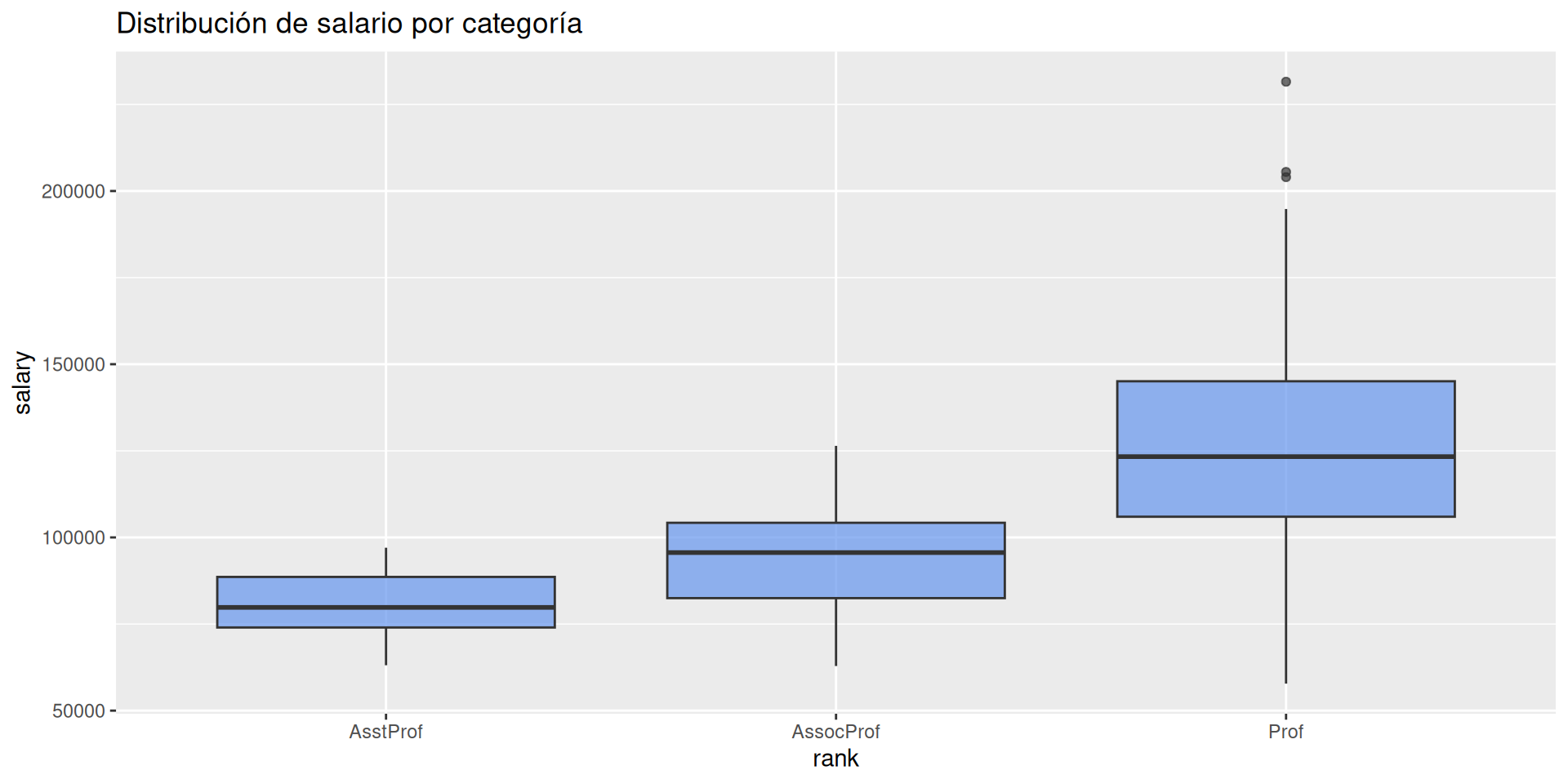
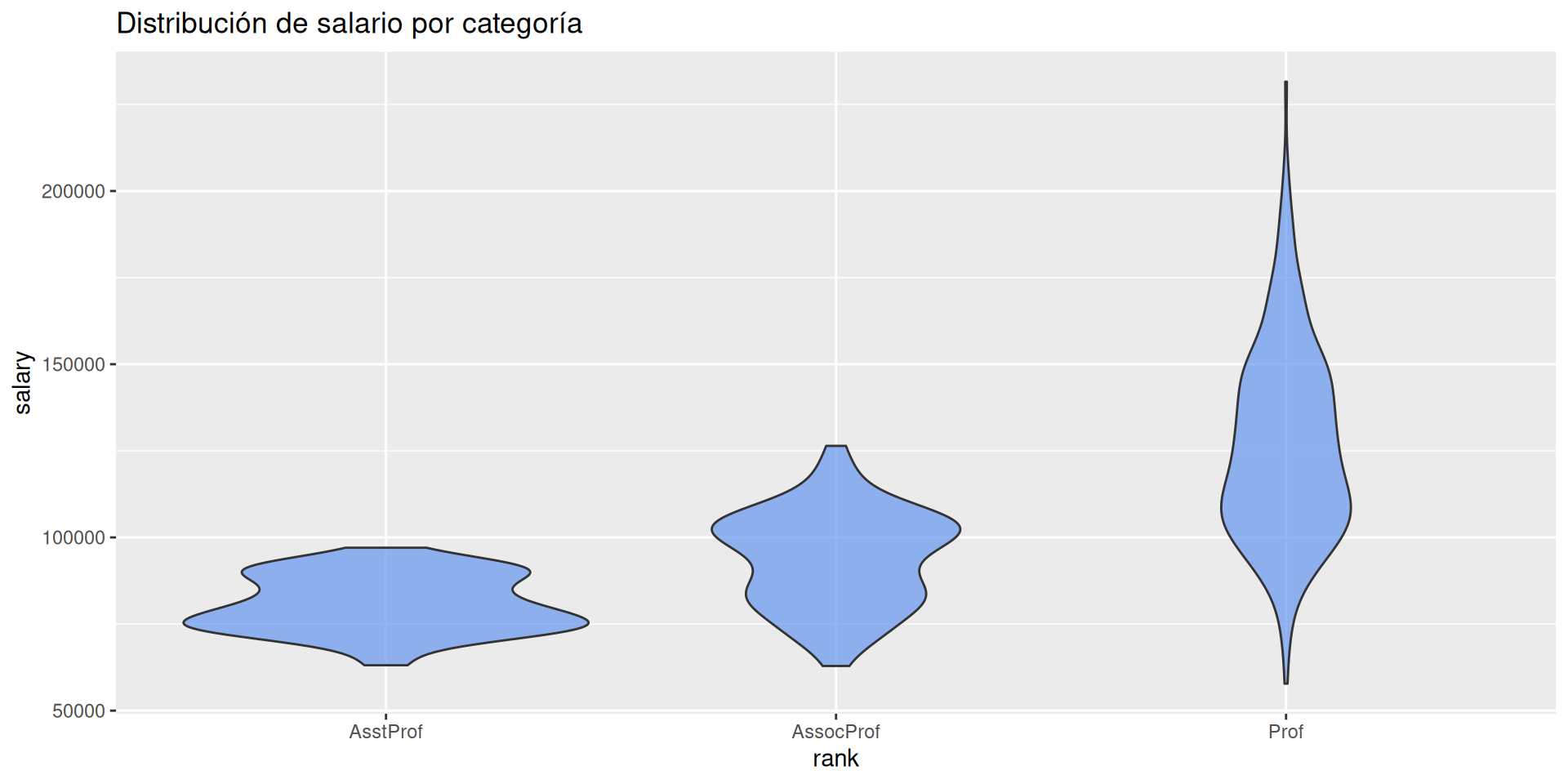
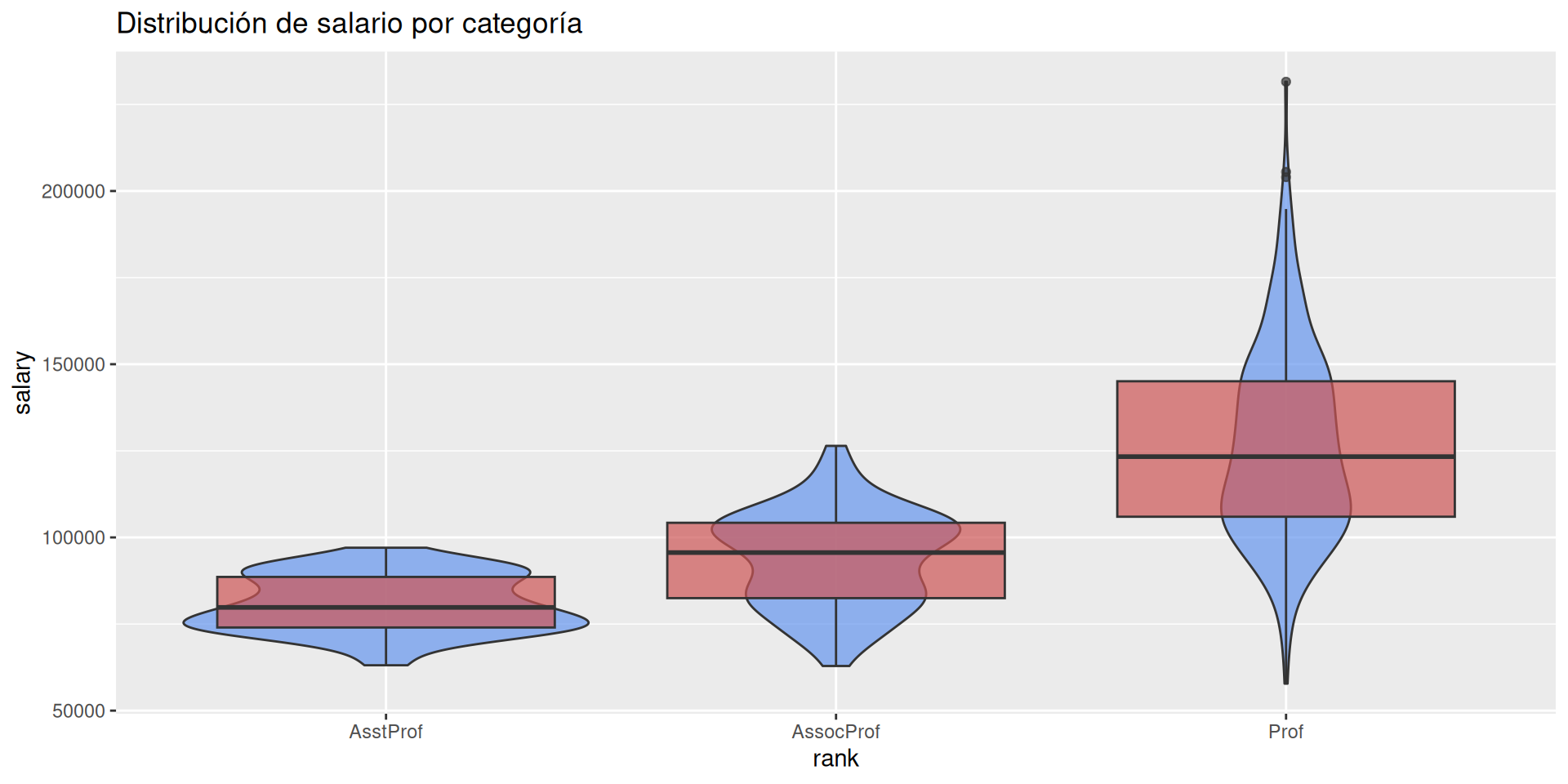
Cuantitativas: Distribución, diagramas de box-plot ó violin.
Diagrama de Barras
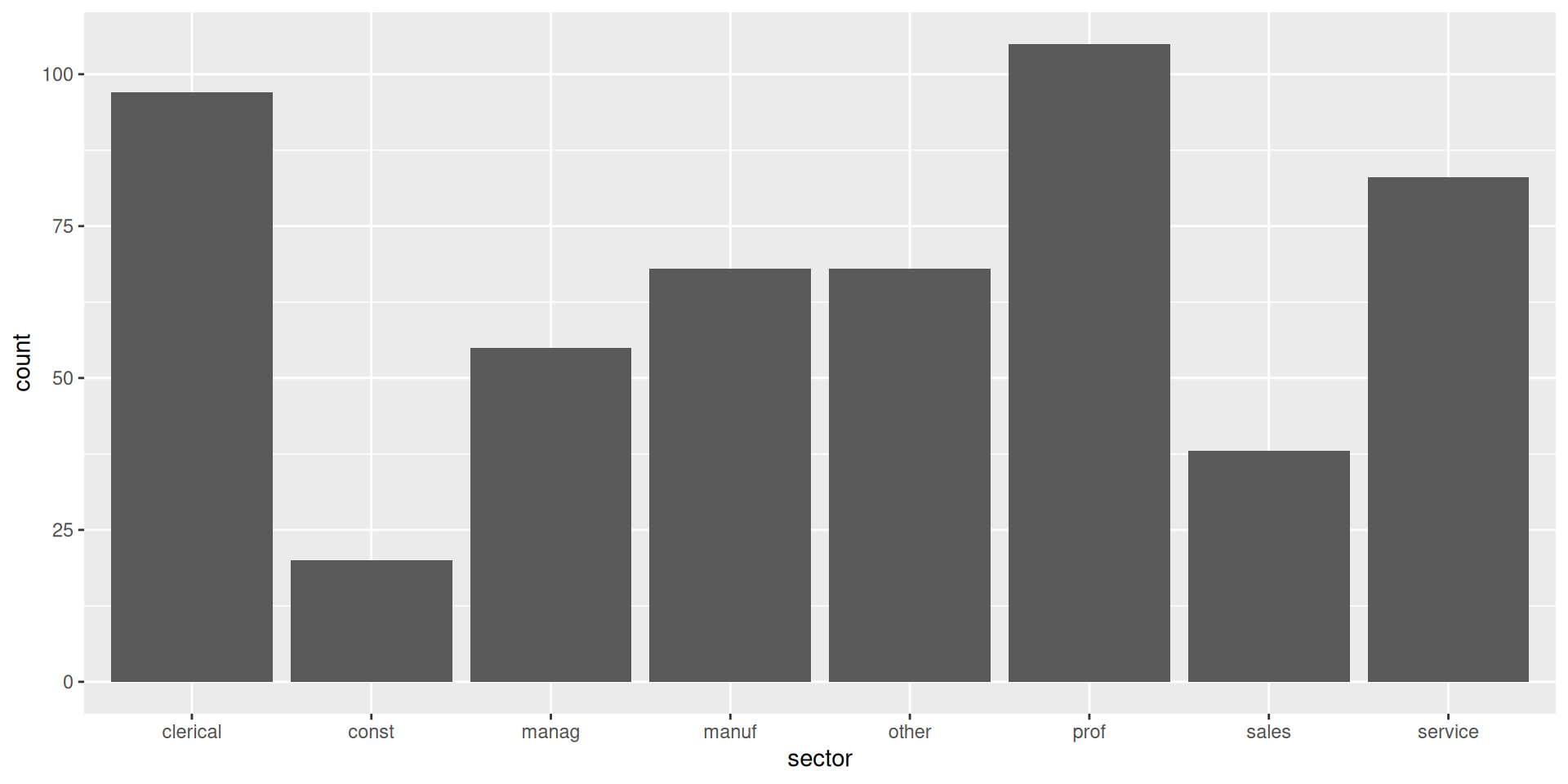
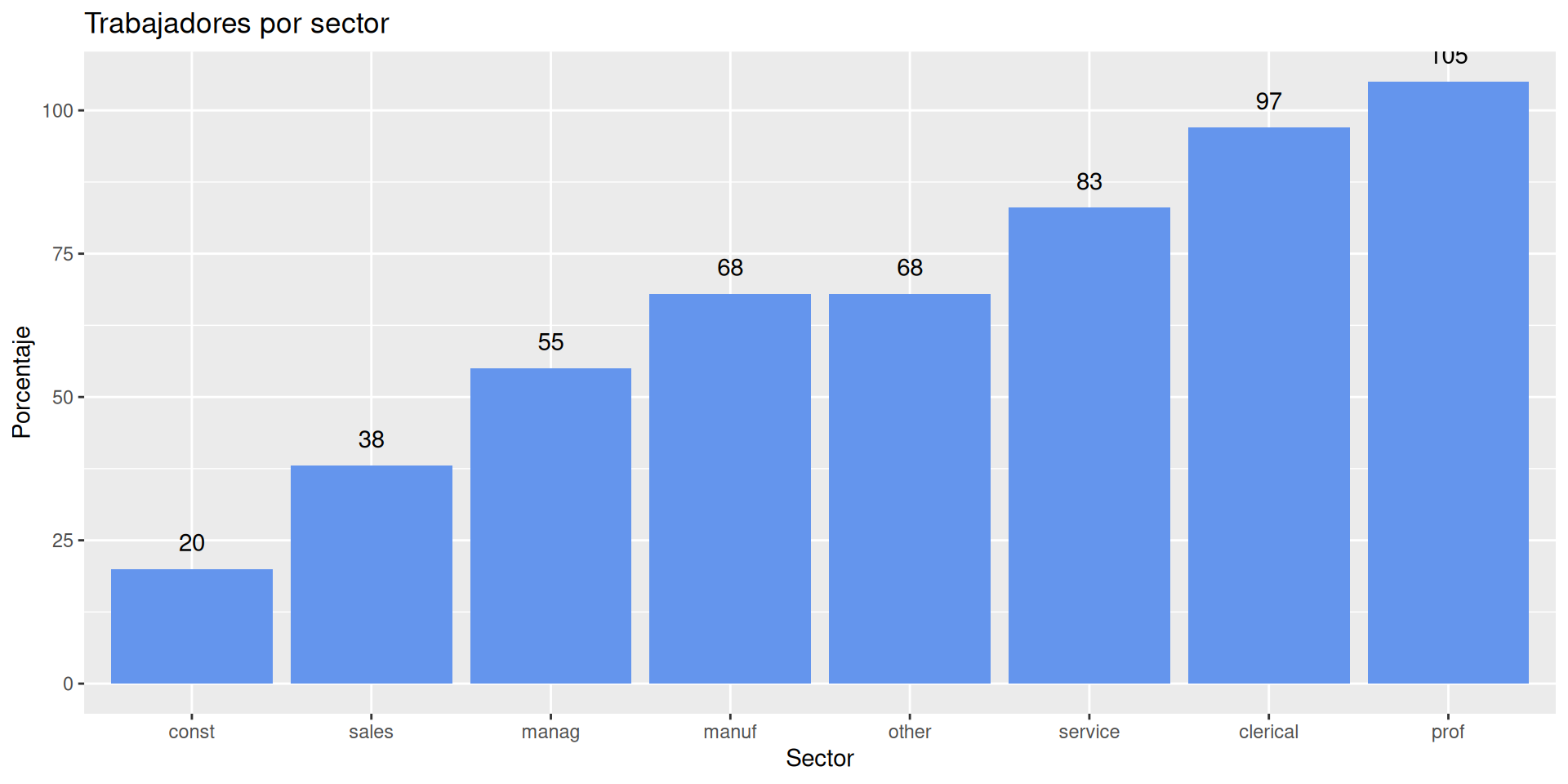
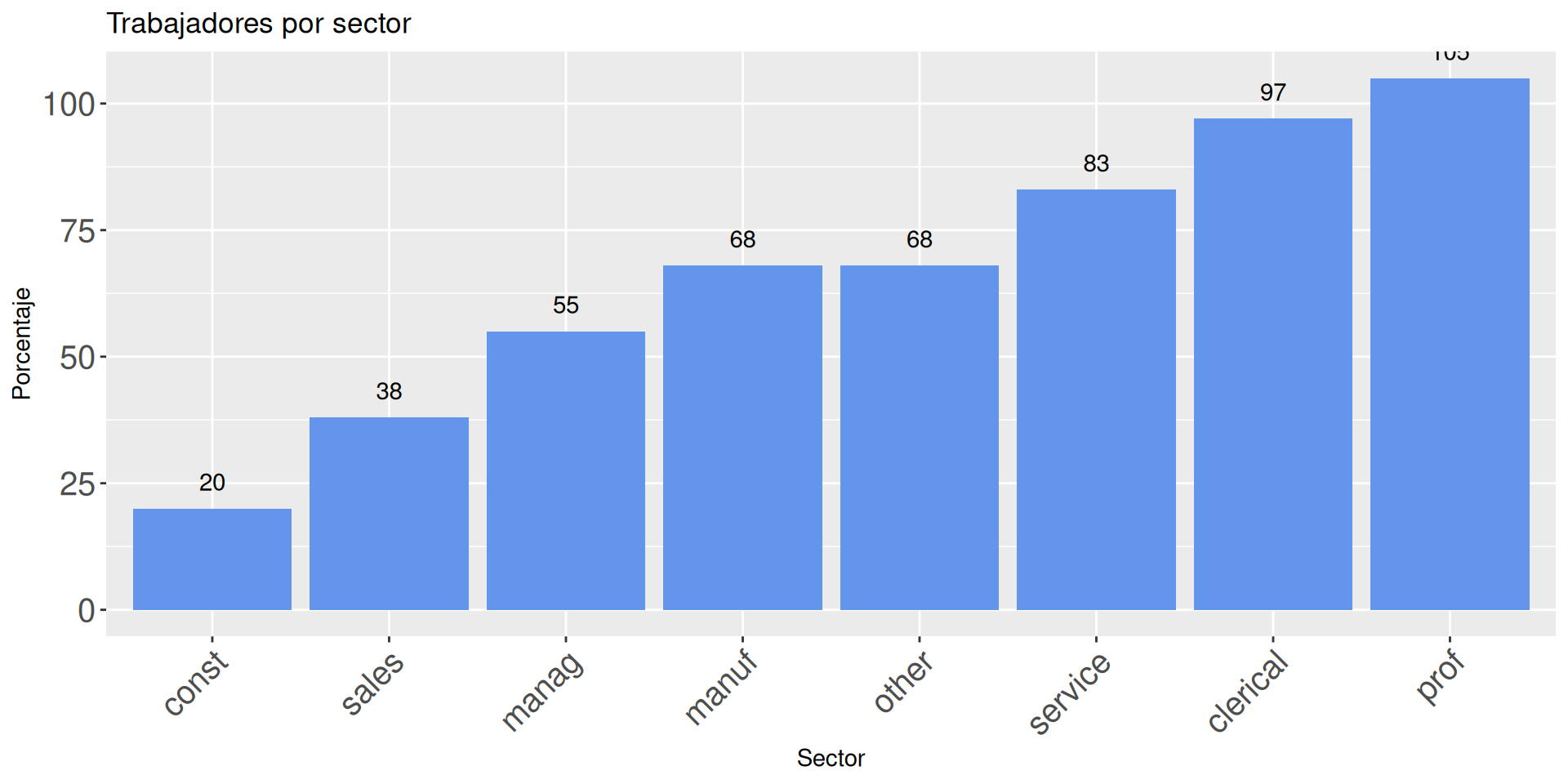
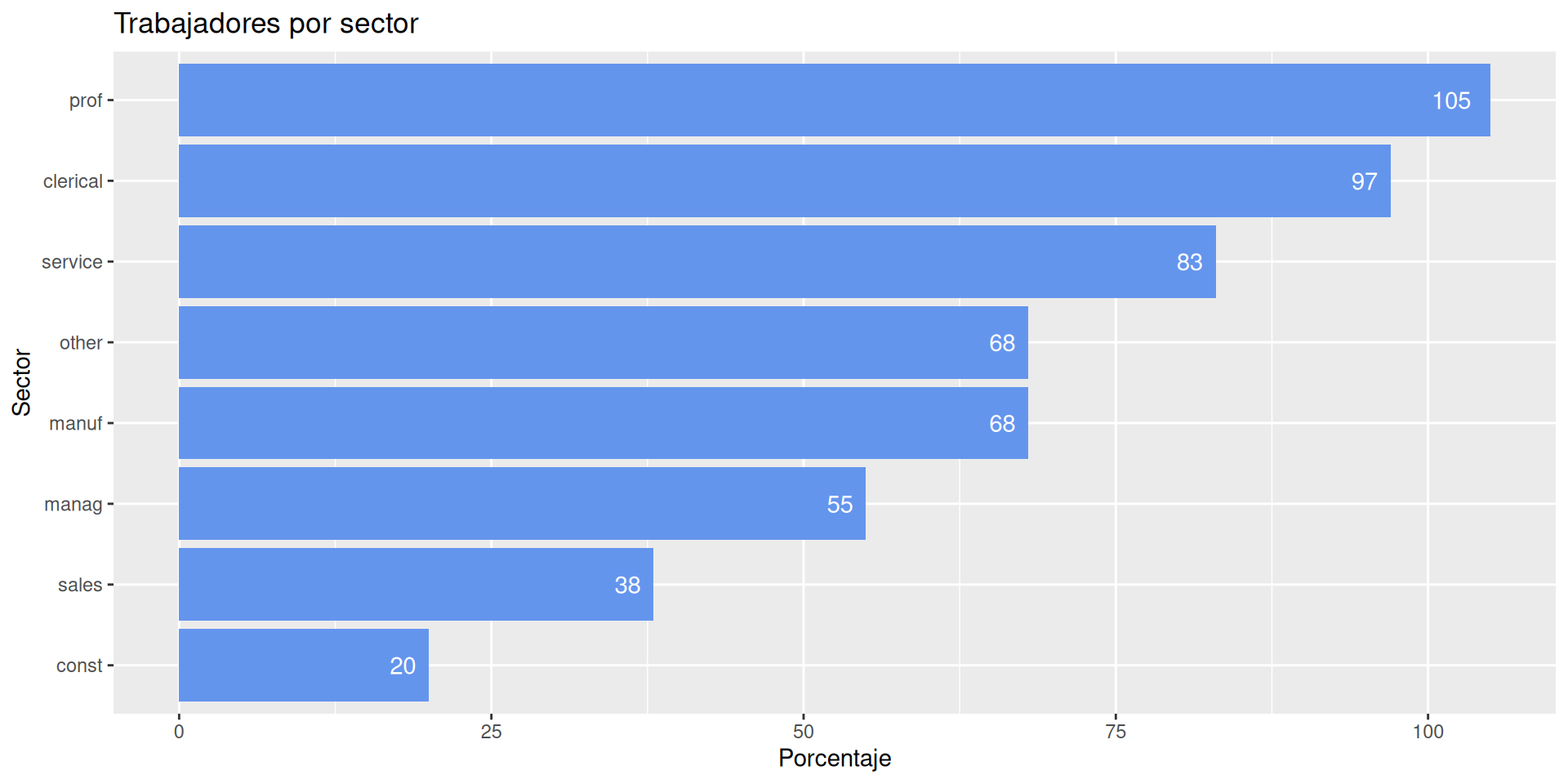
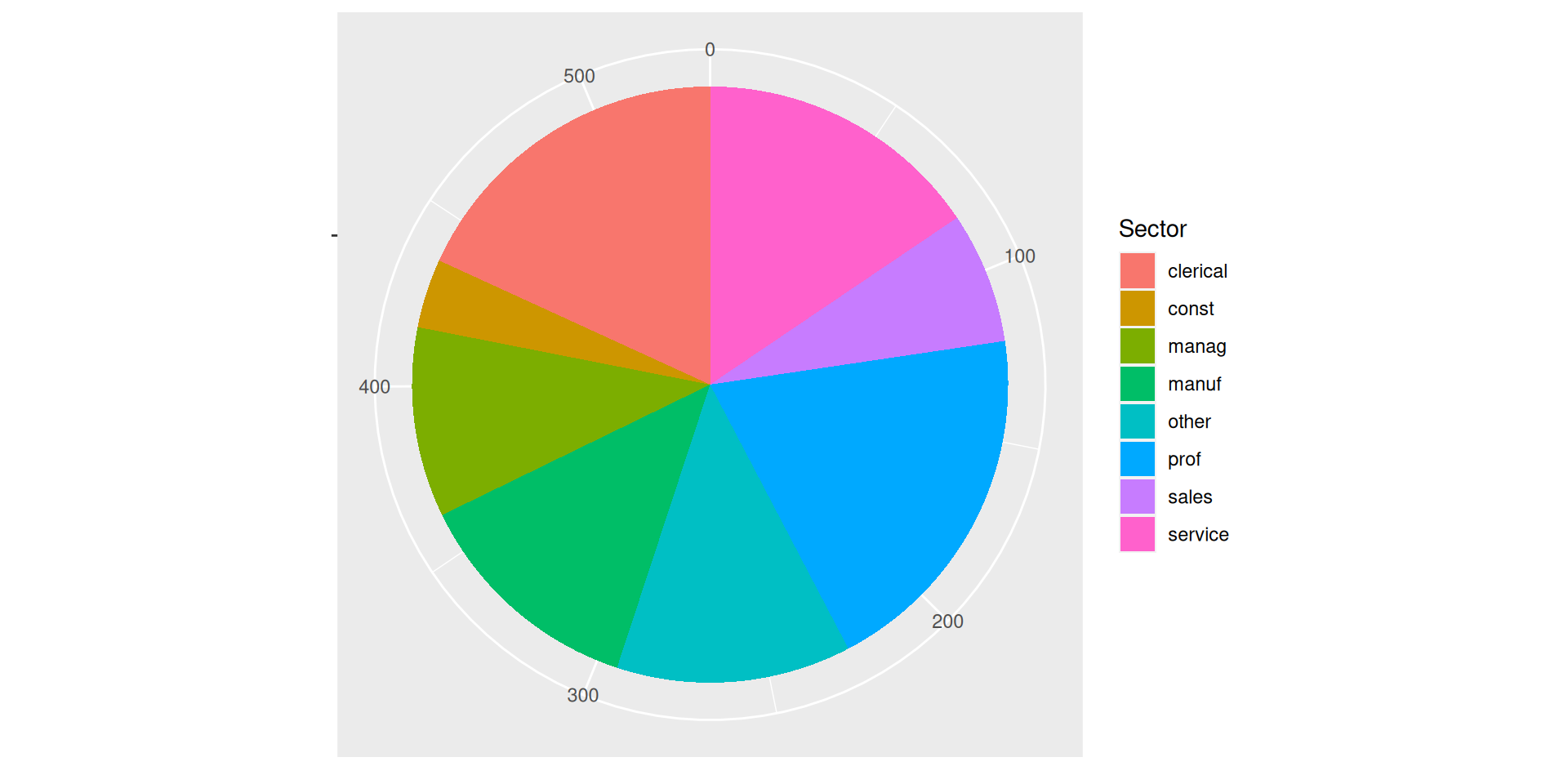
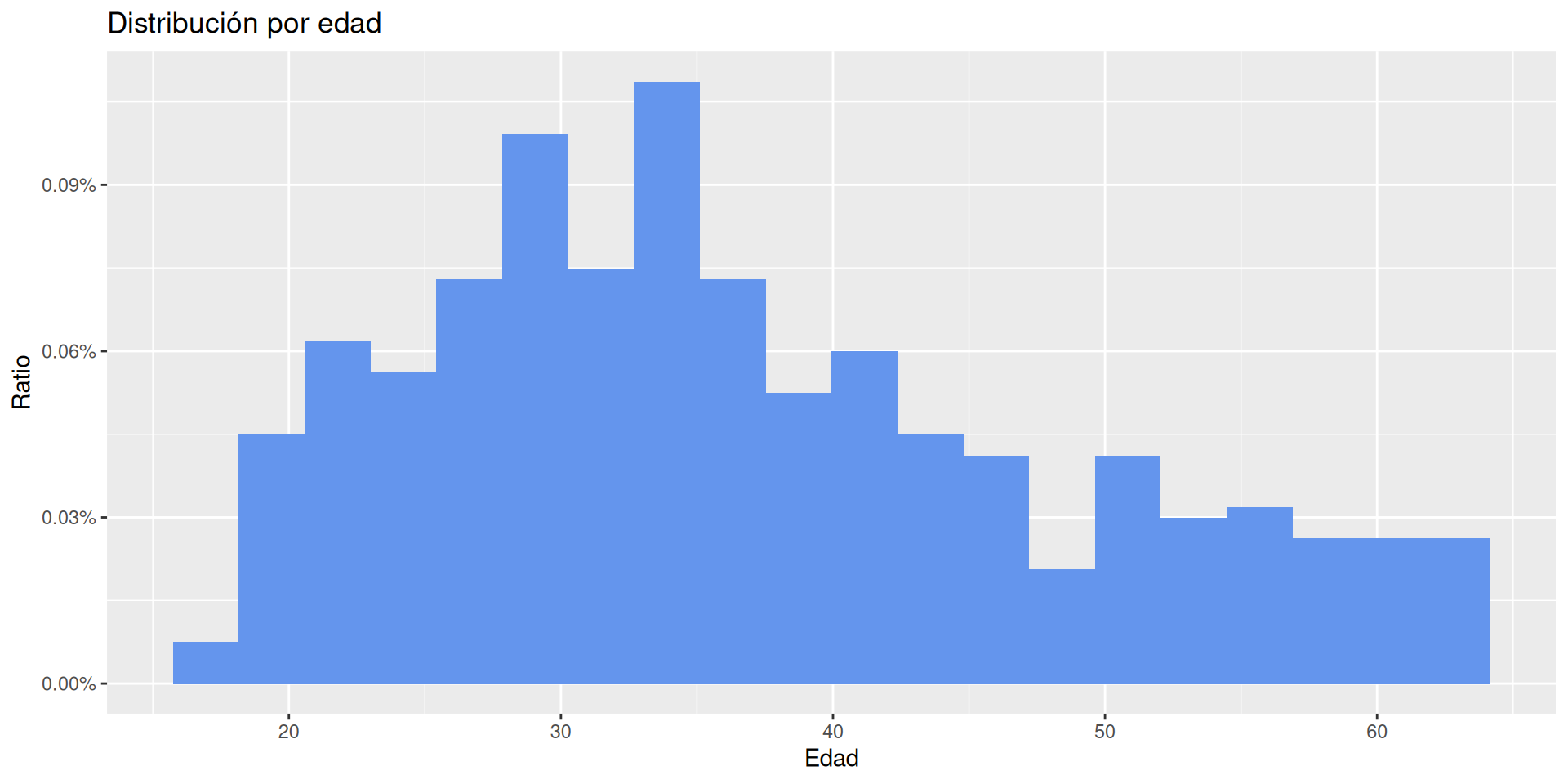
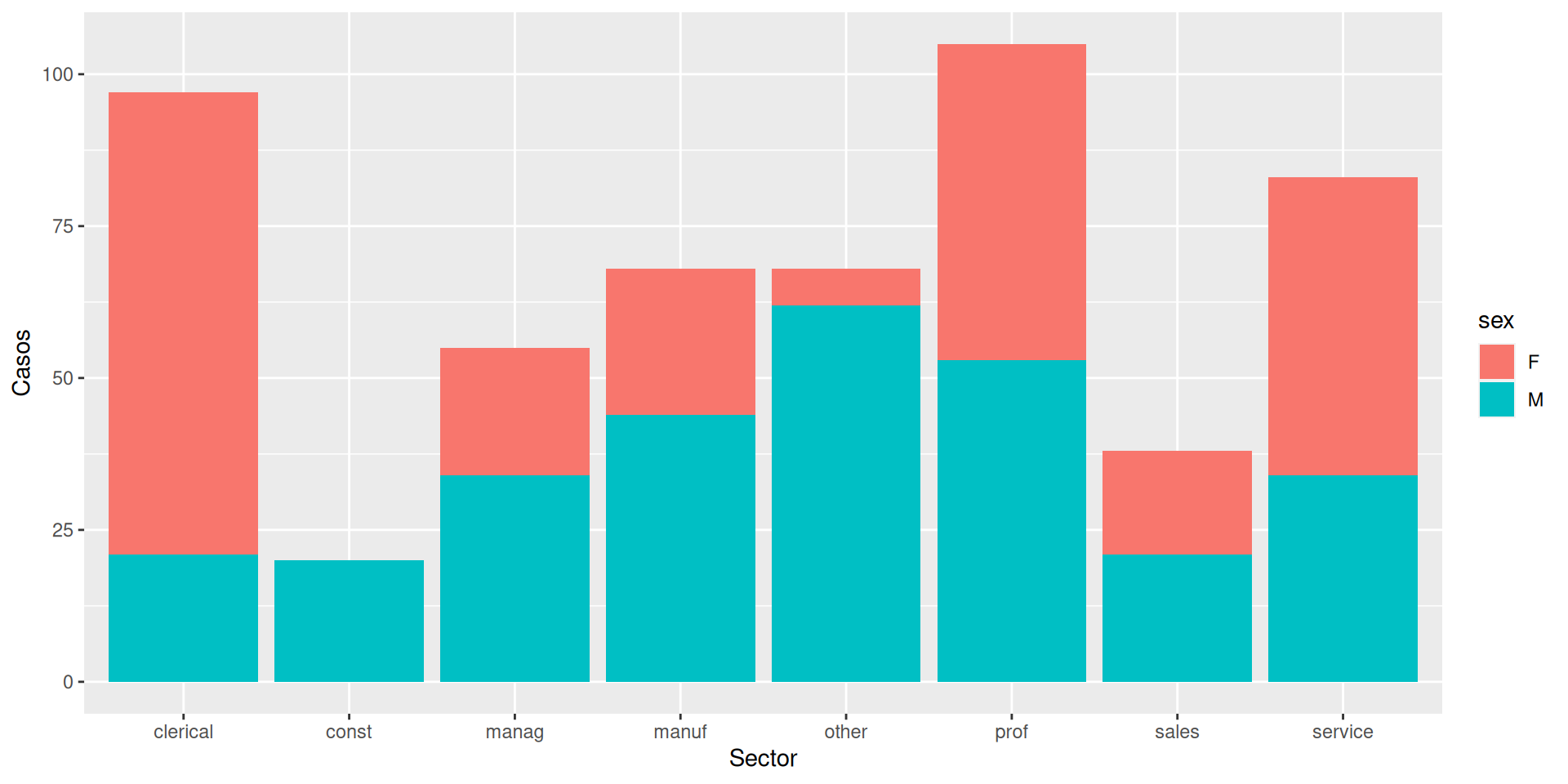
Vamos a estudiar cómo se distribuyen los ejemplos por sector. Usamos para ello geom_bar.
ggplot(df, aes(x = sector)) +geom_bar()
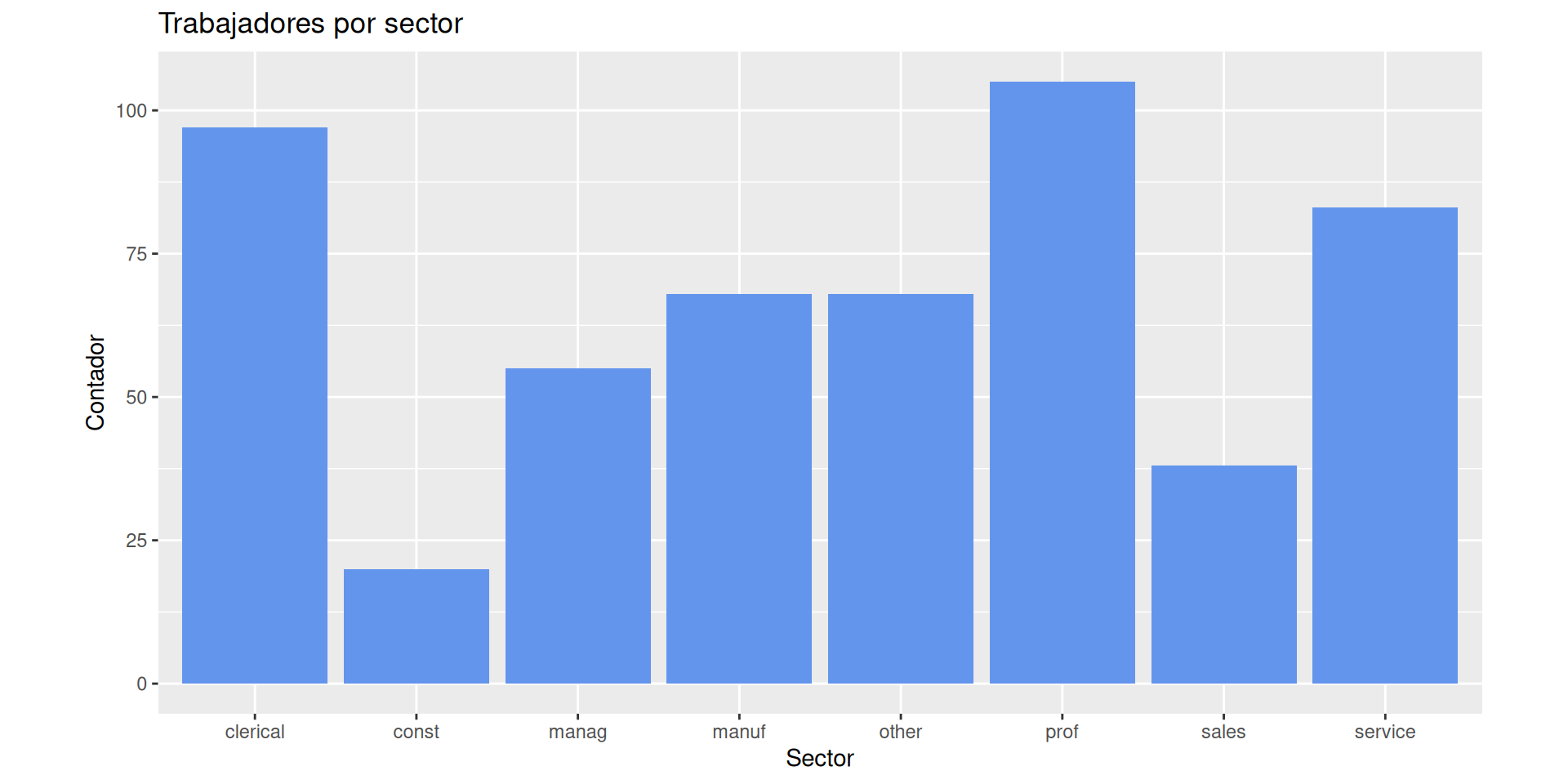
Vamos a ponerlo más bonito:
Usando labs.
Cambiando el color de relleno fill en geom_bar.
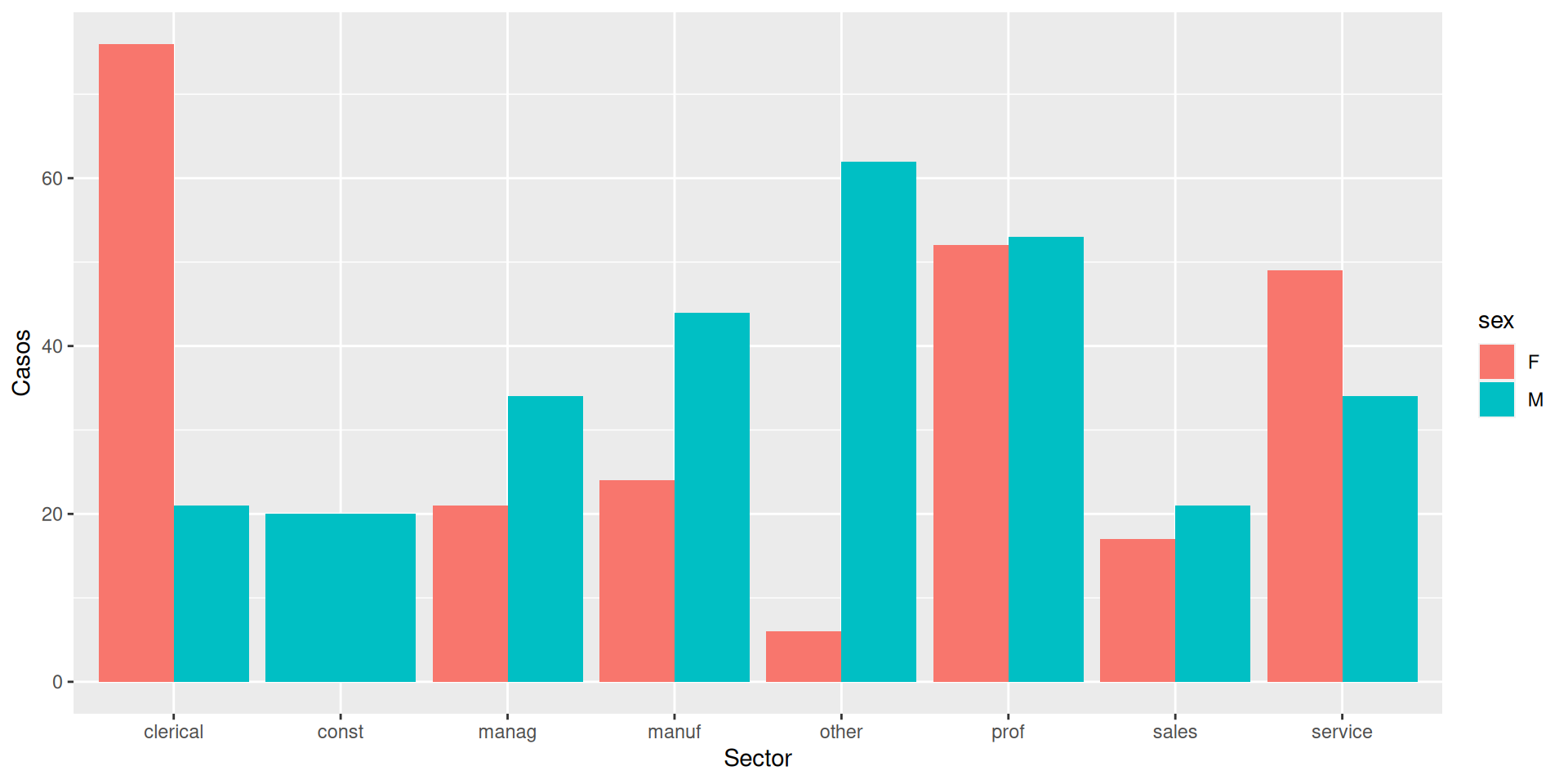
ggplot(df, aes(x = sector)) +theme(aspect.ratio=.5) +geom_bar(fill="cornflowerblue") +labs(x ="Sector", y ="Contador", title="Trabajadores por sector")
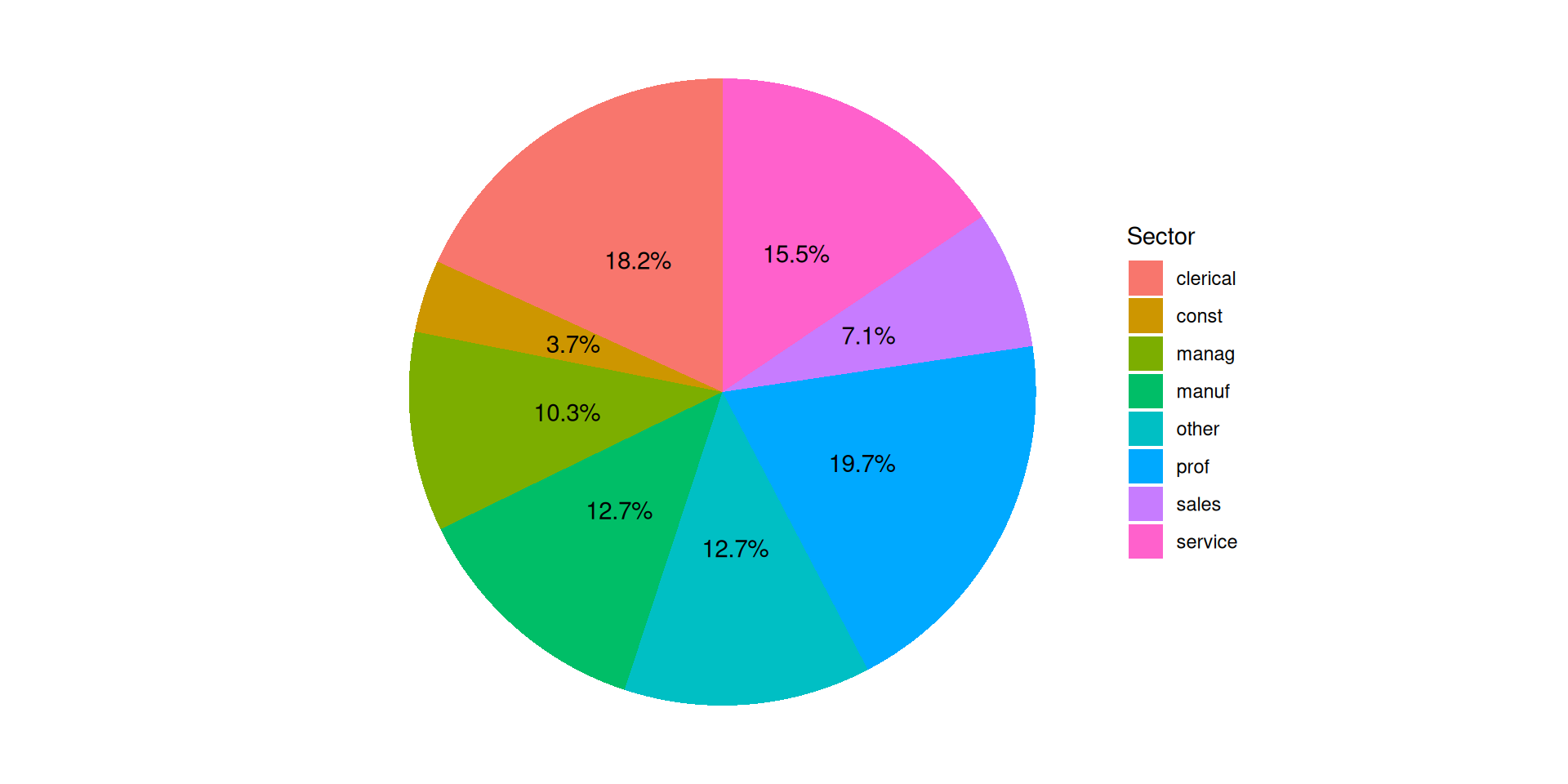
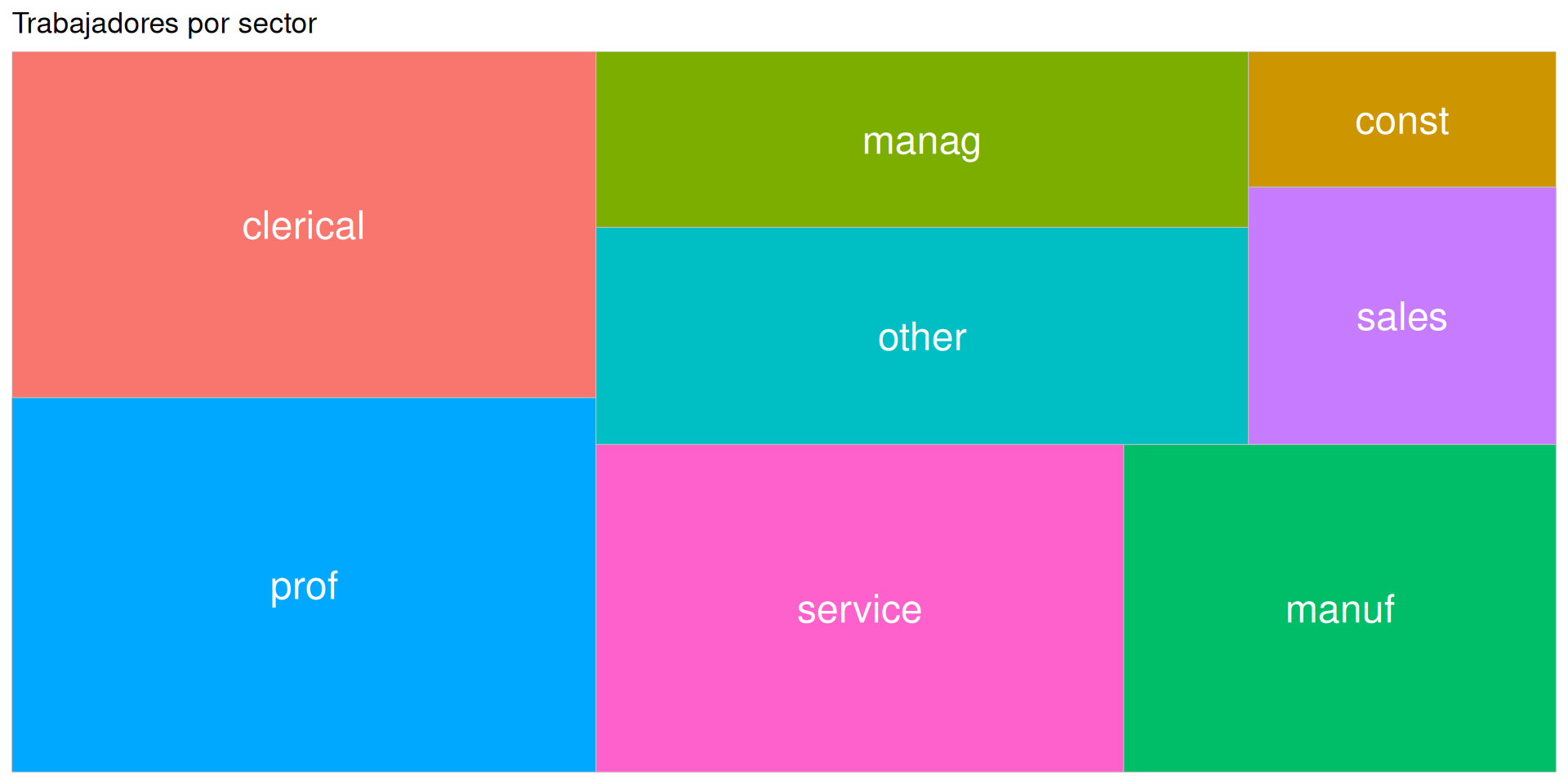
Versión final, ordenado y con valores:
ggplot(df %>%count(sector), aes(x =reorder(sector, n), y=n)) +geom_bar(fill="cornflowerblue", stat="identity") +geom_text(aes(label=n), vjust=-1) +labs(x ="Sector", y ="Porcentaje", title="Trabajadores por sector")
En tips.csv existen datos de consumo en un restaurante. Indica para cada consumición el precio total_bill, la propina y datos del cliente (sex, smoker), el día de la semana, y la hora (Lunch, Dinner).
Ejercicios de visualización
Ejercicios:
Visualizar la distribución de ejemplos por día y por hora.
Visualizar la propina en base a la factura.
Crear el ratio de la propina respecto a la factura.
Mostrar la variación del ratio en base
Gráfico anterior distinguiendo por sexo y fumador en la misma.
Visualizar de forma separada los precios y ratio (con facet_wrap) en base a la hora.
Ejercicios de visualización
Mostrar con barra “stack” el porcentaje de fumadores por sexo.
Mostrar con boxplot y violin la relación en base a la hora y día.