Nomenclatura
En la documentación suele aparecer fig y axis, cuidado.
fig: Es todo el área a pintar (una o varias figuras juntas).
axis: Es realmente una figura, no unas coordenadas.
Hay un interfaz más básico, pero lo mejor es el moderno, que permite crear fácilmente subfiguras:
from matplotlib import pyplot as pltimport seaborn as snsimport altair as altimport numpy as np
Imagen de ejemplo
= plt.subplots()1 ,2 ,3 ,4 ],[10 ,15 ,20 ,30 ])"Figura de ejemplo" )"Eje X" )"Eje Y" )
Se pueden crear varias figuras
= plt.subplots(1 , 2 )= np.arange(10 )0 ].plot(x,x+ np.ones(len (x)))1 ].plot(x, np.power(x,2 ))0 ].set_title("Lineal" )1 ].set_title("Cuadrado" )
Visualizando
Vamos a cargar un dataset clásico y luego analizarlo con visualizaciones.
Uno con datos sobre sueldos.
import pandas as pd= pd.read_csv("CPS85.csv" )print (pop.columns.tolist())3 )
['wage', 'educ', 'race', 'sex', 'hispanic', 'south', 'married', 'exper', 'union', 'age', 'sector']
wage
educ
race
sex
hispanic
south
married
exper
union
age
sector
0
9.0
10
W
M
NH
NS
Married
27
Not
43
const
1
5.5
12
W
M
NH
NS
Married
20
Not
38
sales
2
3.8
12
W
F
NH
NS
Single
4
Not
22
sales
Otro dataset son distintos pingüinos. Es un problema de clasificación (specie ) similar al iris .
= sns.load_dataset("penguins" )print (penguins.columns.tolist())3 )
['species', 'island', 'bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex']
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
0
Adelie
Torgersen
39.1
18.7
181.0
3750.0
Male
1
Adelie
Torgersen
39.5
17.4
186.0
3800.0
Female
2
Adelie
Torgersen
40.3
18.0
195.0
3250.0
Female
Seaborn
Antes de empezar comento algunas características:
Las funciones trabajan con un DataFrame, por medio del parámetro data.
Se puede identificar para cada dimensión, color, tamaño, … el nombre de un atributo.
Se pueden crear distintas figuras (por filas, columnas, …).
Hay un excelente tutorial online en https://seaborn.pydata.org/tutorial/introduction.html .
Es muy potente:
= sns.load_dataset("dots" )= dots, kind= "line" ,= "time" , y= "firing_rate" , col= "align" ,= "choice" , size= "coherence" , style= "choice" ,= dict (sharex= False ),
Posee muchas funciones distintas:
scatterplot: Visualización de instancias como puntos.
lineplot: Visualiza las instancias como puntos.
lmplot: Visualiza como puntos, y lo aproxima.
barplot: Diagramas de barras (incluyendo líneas de error).
swarmplot: Visualiza en forma de violín.
boxplot: Distribución usando boxplot.
…
Sin embargo, es mejor limilarse a tres funciones:
Se distingue el concreto mediante el parámetro kind .
Ventajas: permite múltiples figuras a la vez según un criterio.
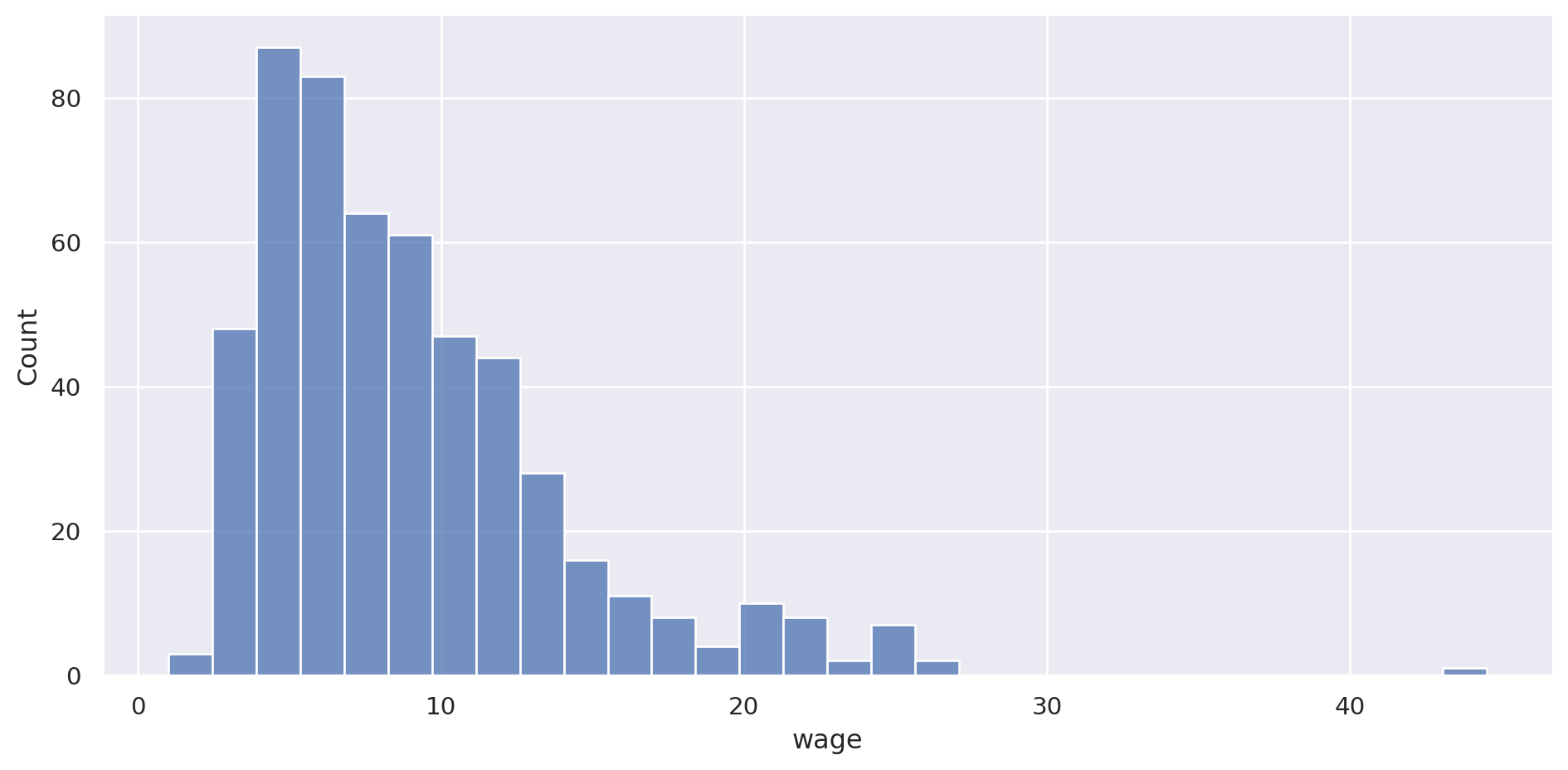
Visualizando sueldos
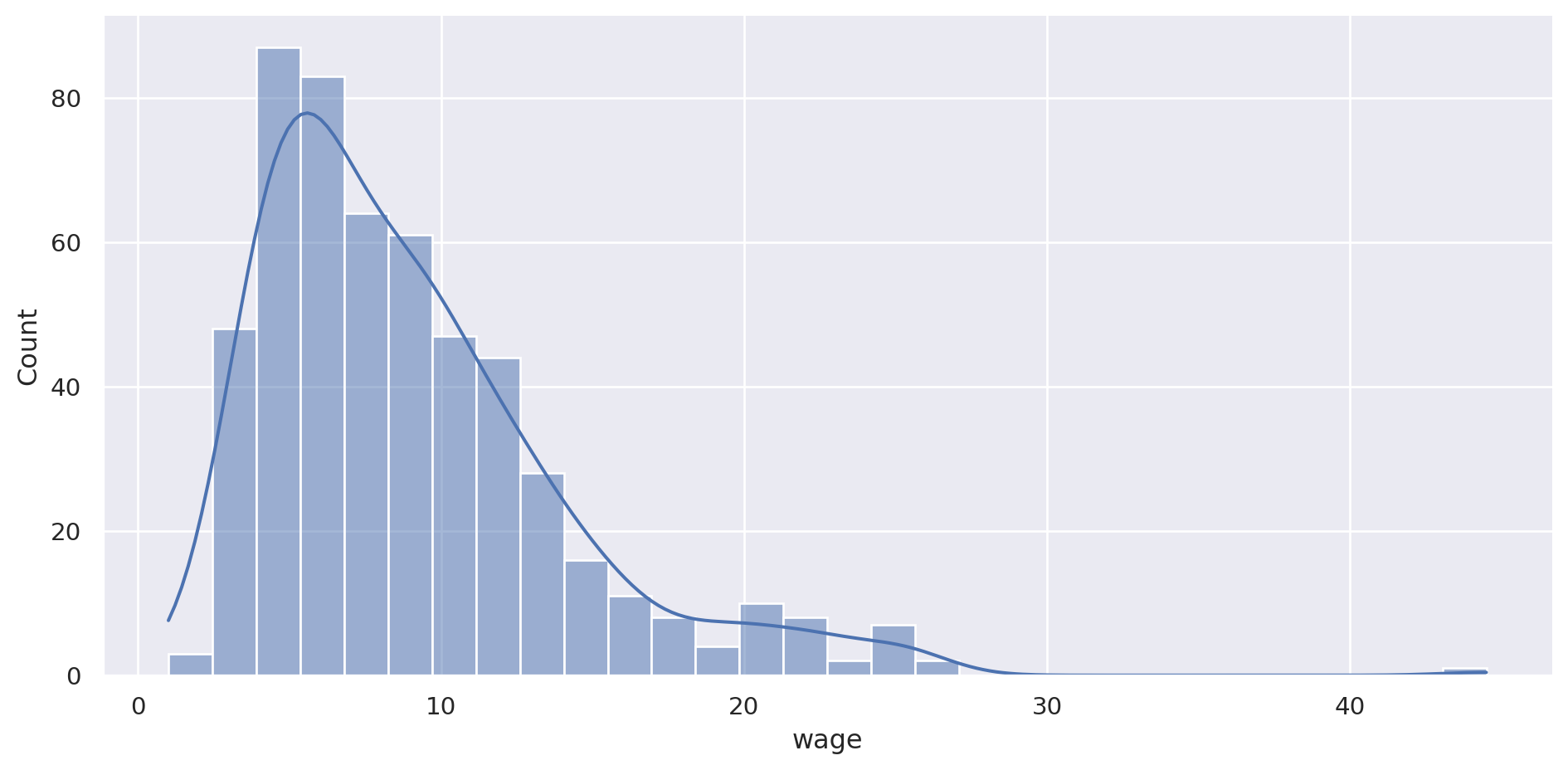
Es una distribución, por tanto usamos displot .
= "wage" , data= pop, aspect= 2 )
Se puede añadir como función kde.
= "wage" , data= pop, aspect= 2 , kde= True )
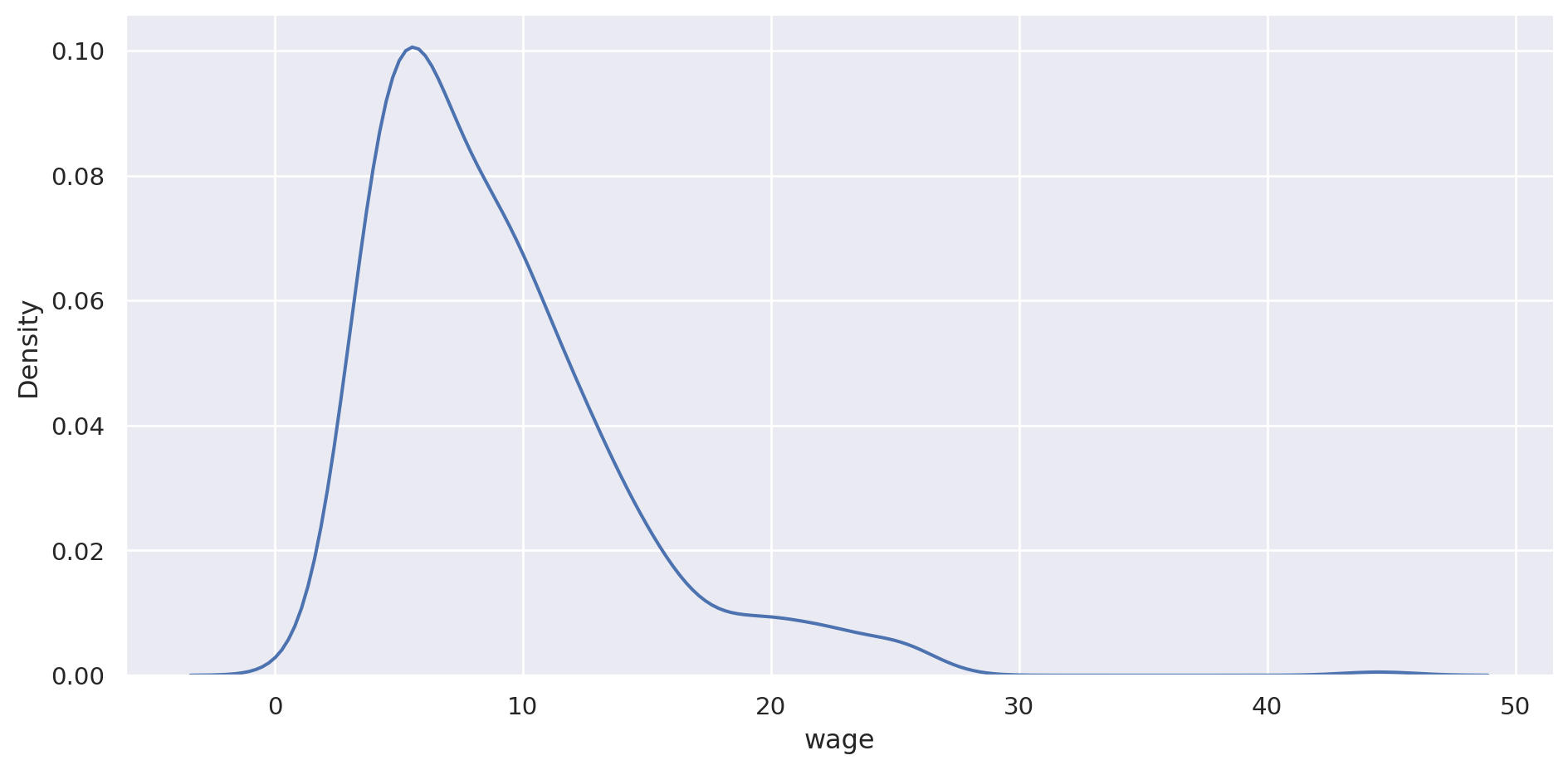
O directamente solo el kde:
= "wage" , data= pop, aspect= 2 , kind= "kde" )
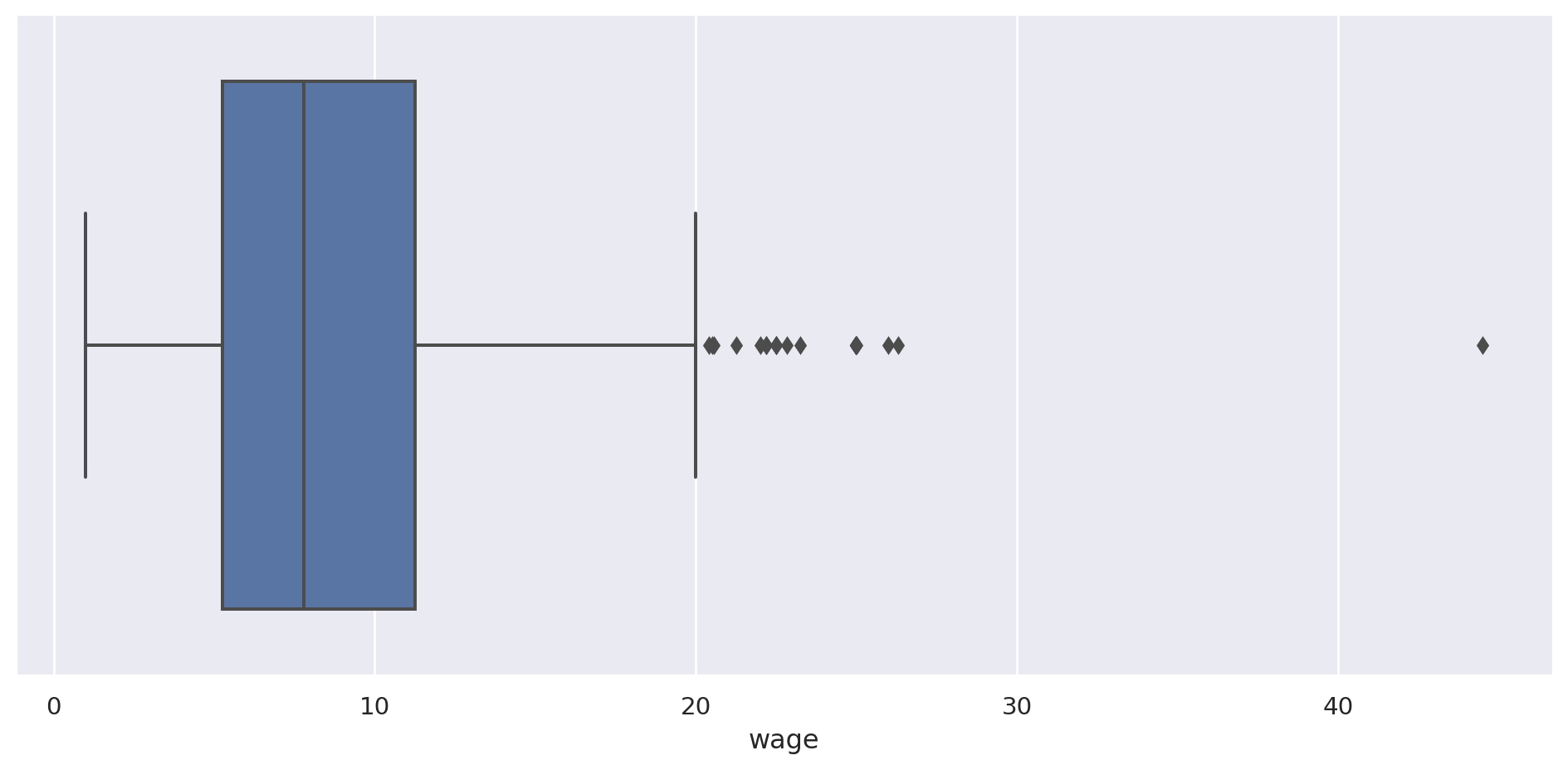
También podríamos mostrarlo de valor categórico:
= "wage" , data= pop, aspect= 2 , kind= "box" )
Altair
Altair tiene una sintaxis muy homogénea:
Ventajas:
Permite aplicar transformaciones.
Permite poner en una variable expresión (count(), max(), …).
Sintaxis muy homogénea.
La sintaxis es:
= ...= ...
Donde mark_xxx puede ser:
mark_lines: Líneas.
mark_points: Versión con puntos.
mark_bar: Diagrama de barras.
mark_boxplot: Diagrama boxplot.
…
Definir el tipo de un datos como ‘Variable :Tipo ’ indicando el tipo de datos.
Tipo:
‘Q’: Valor real.
‘O’: Valor ordinal.
‘N’: Valor como categórico.
Vamos a visualizar las gráficas anteriores con Altair.
'wage:Q' , bin = alt.Bin(step= 1 )),= 'count():O' ,= 800 , height= 400 )
Ahora como líneas.
'wage:Q' , bin = alt.Bin(step= 1 )),= 'count():O' ,= 800 , height= 400 )
Ahora como boxplot.
= 50 ).encode(= 'wage:Q' ,= 800 , height= 400 )
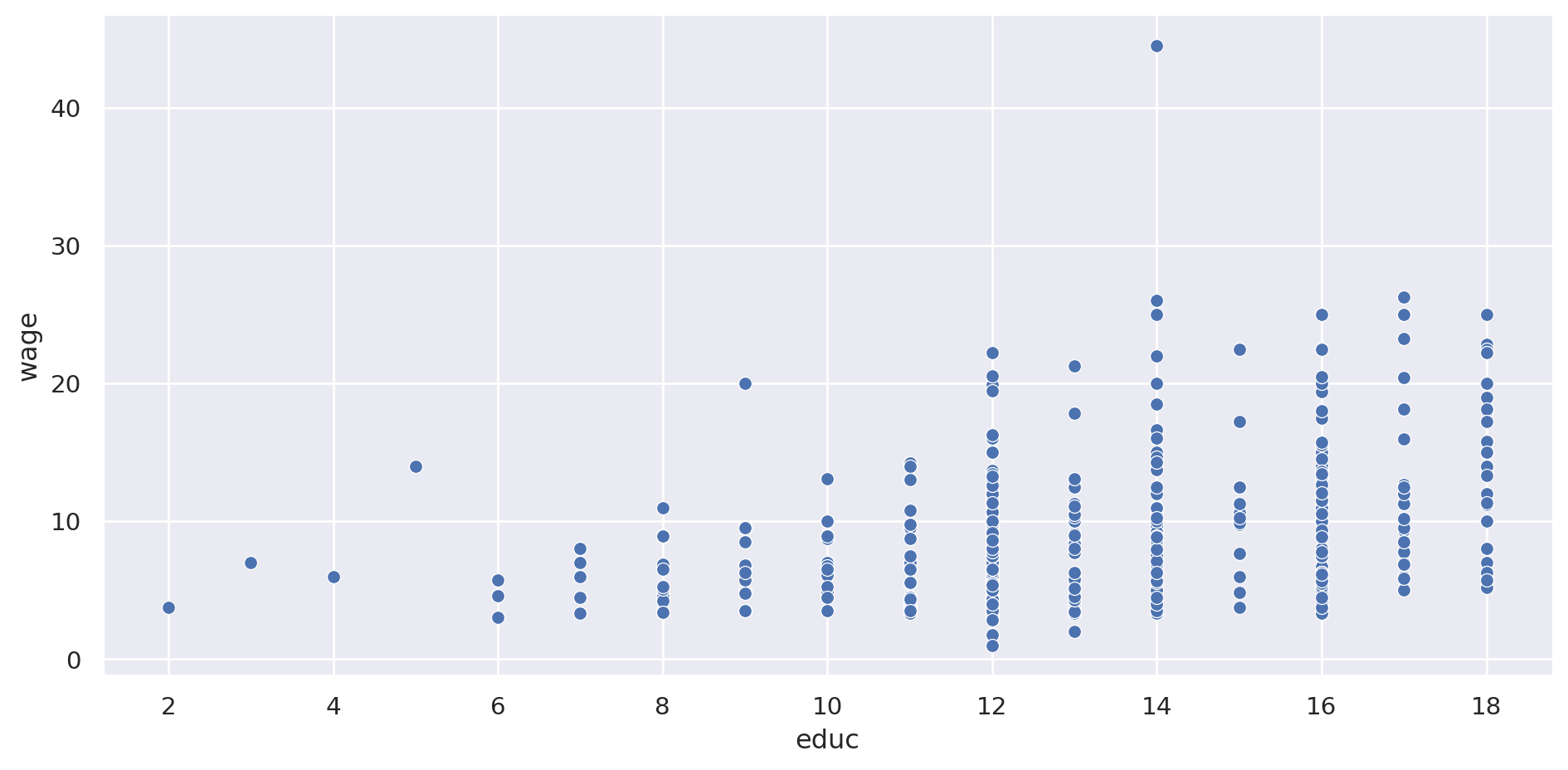
= 'wage:Q' ,= 'educ:Q' ,= 800 , height= 400 )
También permite mostrar la media y remarca el 95% del intervalo de confianza.
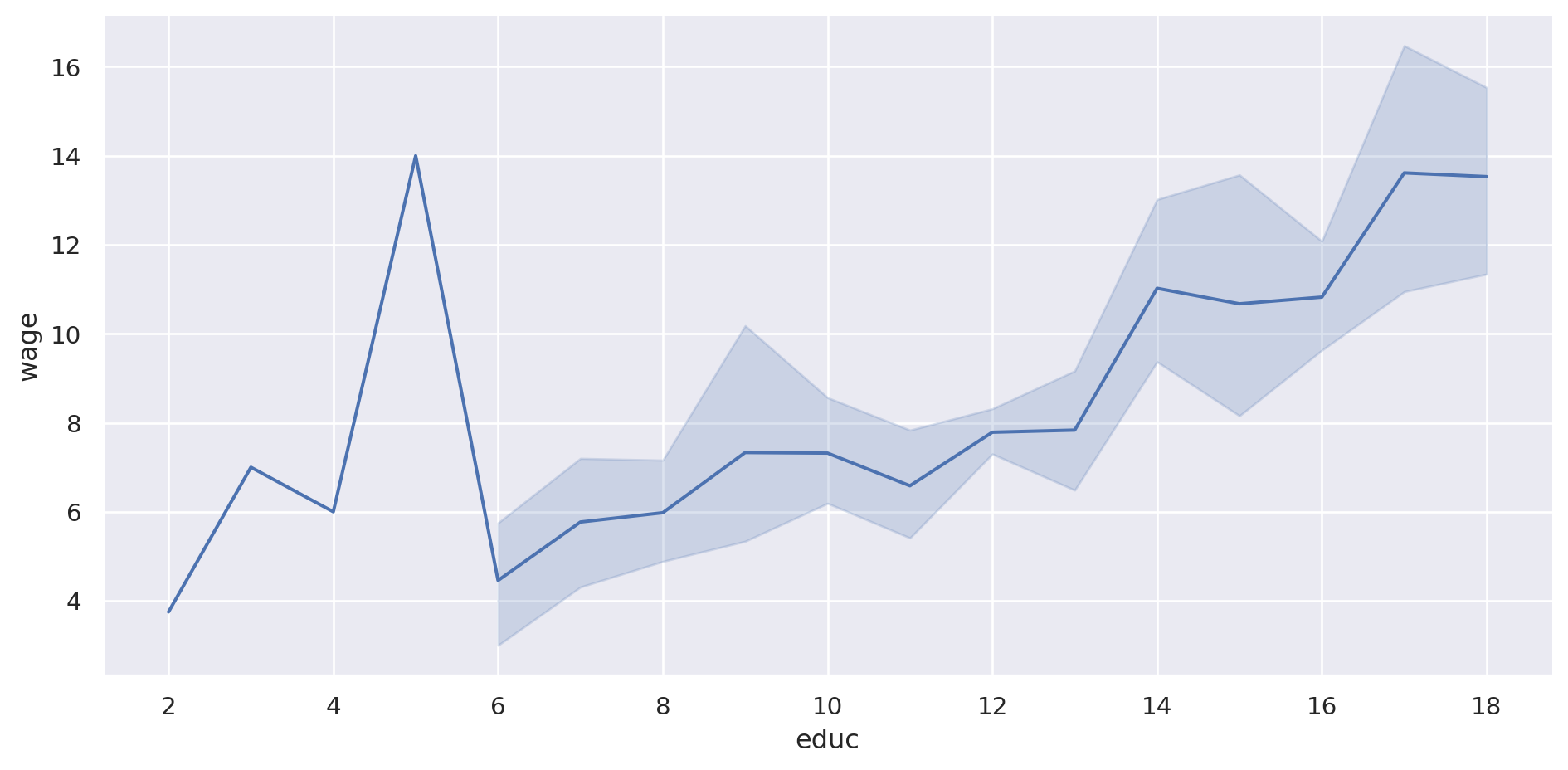
= "educ" , y= "wage" , data= pop, aspect= 2 , kind= "line" )
Directamente se confirma con el box-plot.
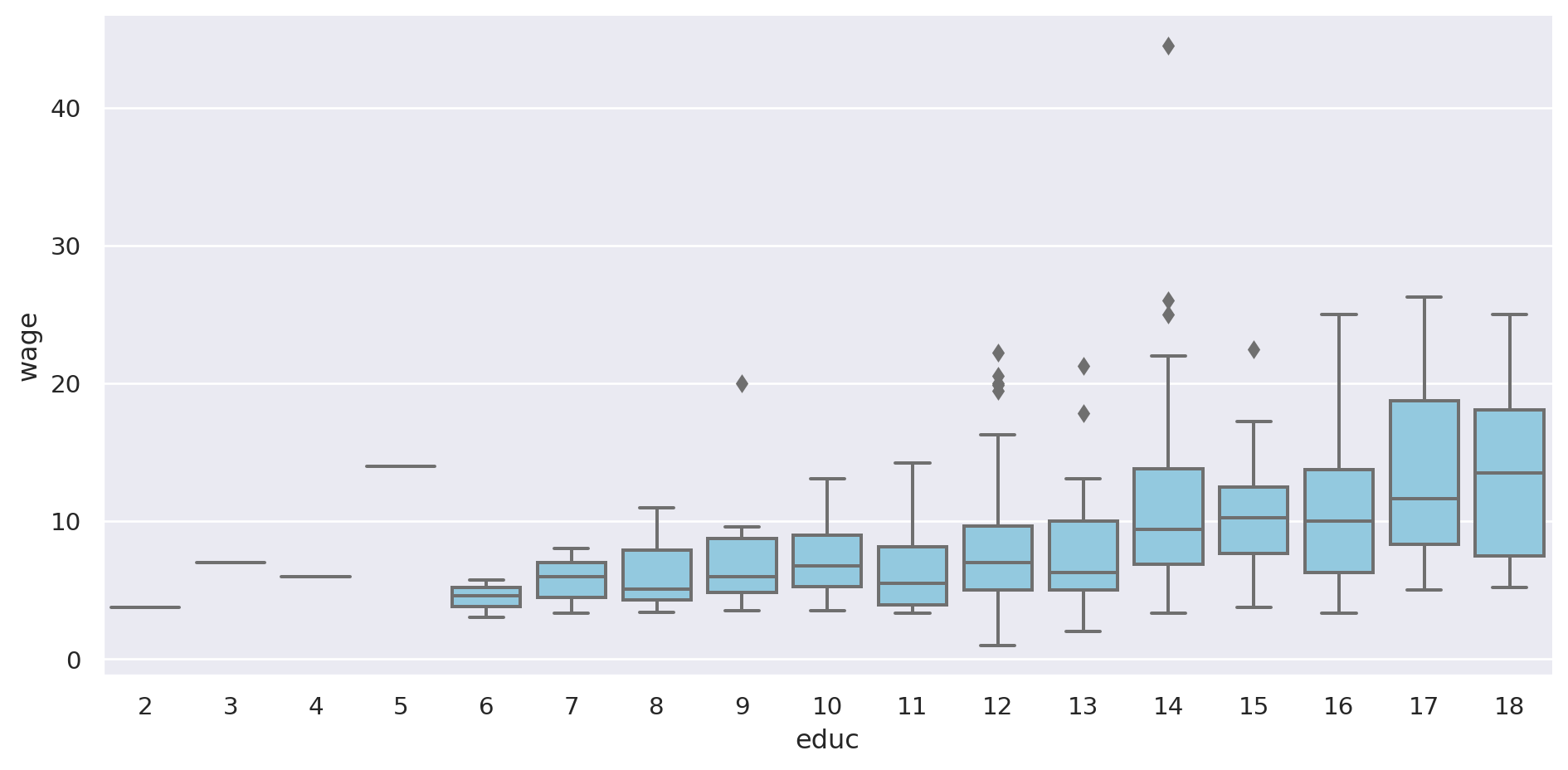
= "educ" , y= "wage" , data= pop, aspect= 2 , kind= "box" , color= "skyblue" )
Se ve que con mayor nivel educativo mayor es la variabilidad.
En Altair es muy directo:
= 30 ).encode(= 'wage:Q' ,= 'educ:Q' ,= 'skyblue' = 800 , height= 400 )
Otra forma, diagrama de barras:
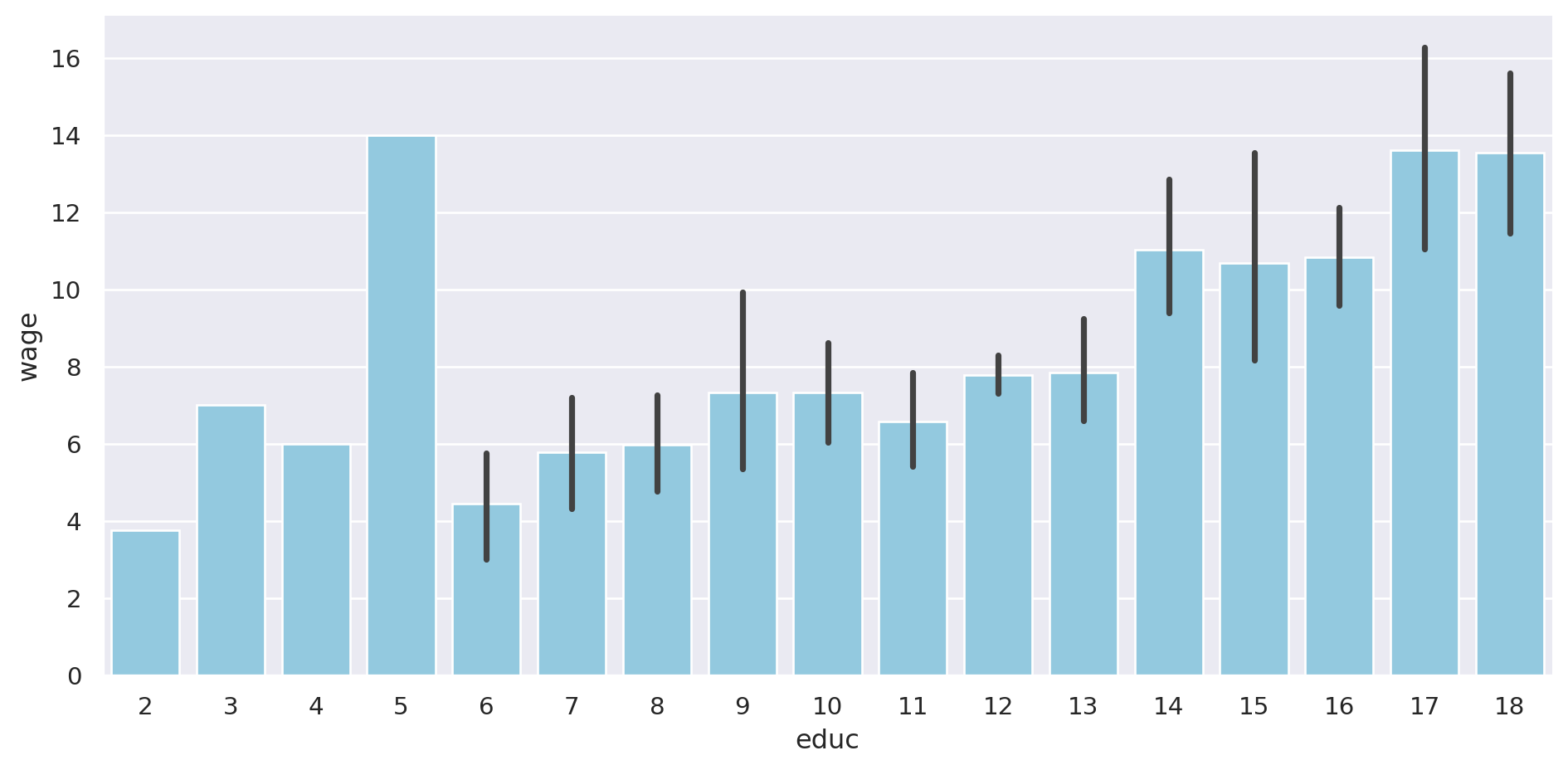
= "wage" , x= "educ" , data= pop, kind= "bar" ,= "skyblue" , aspect= 2 )
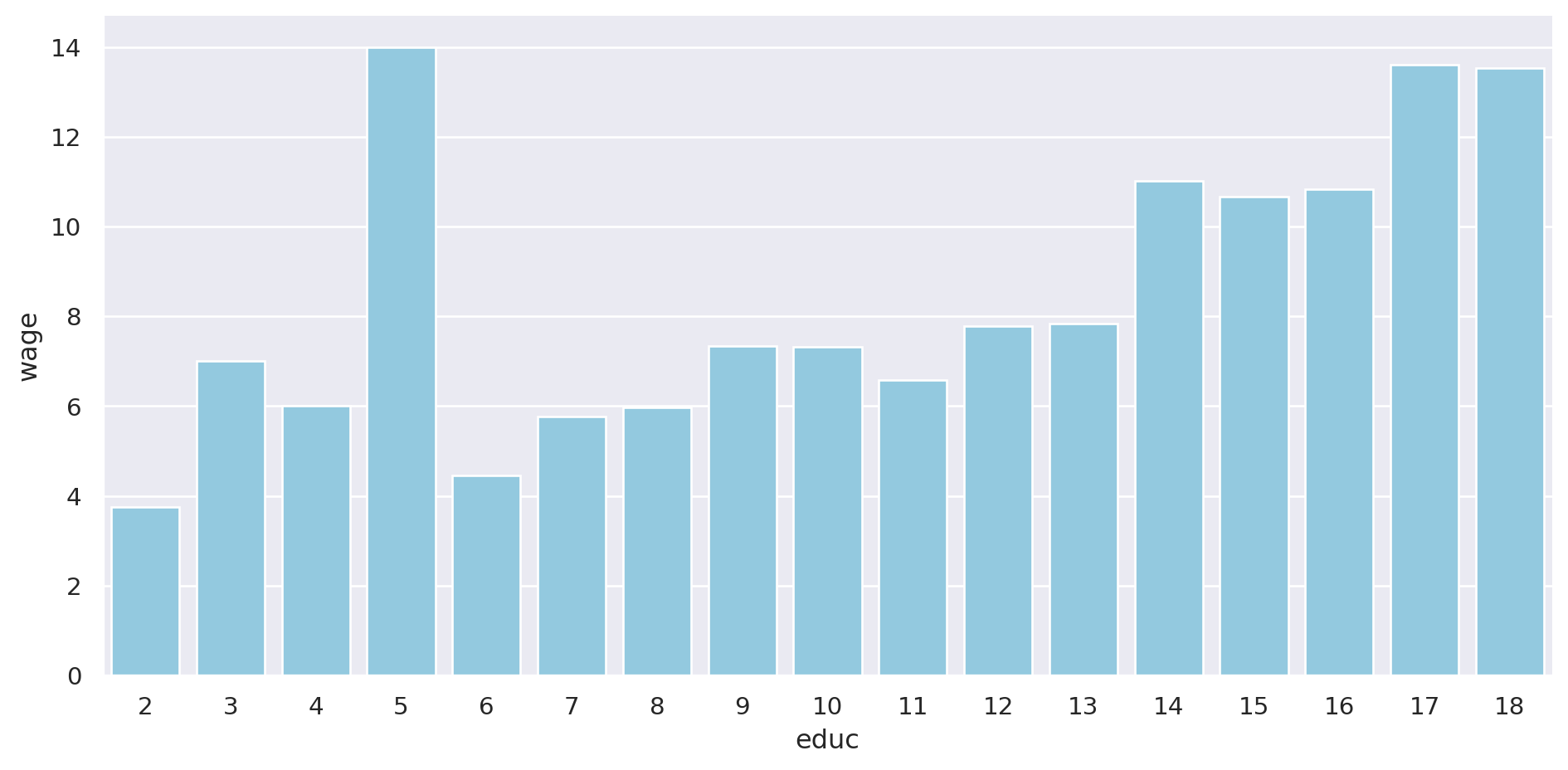
Se pueden quitar las barras de error:
= "wage" , x= "educ" , data= pop, kind= "bar" , errorbar= None ,= "skyblue" , aspect= 2 )
= 30 ).encode(= 'mean(wage):Q' ,= 'educ:Q' ,= 'skyblue' = 800 , height= 400 )
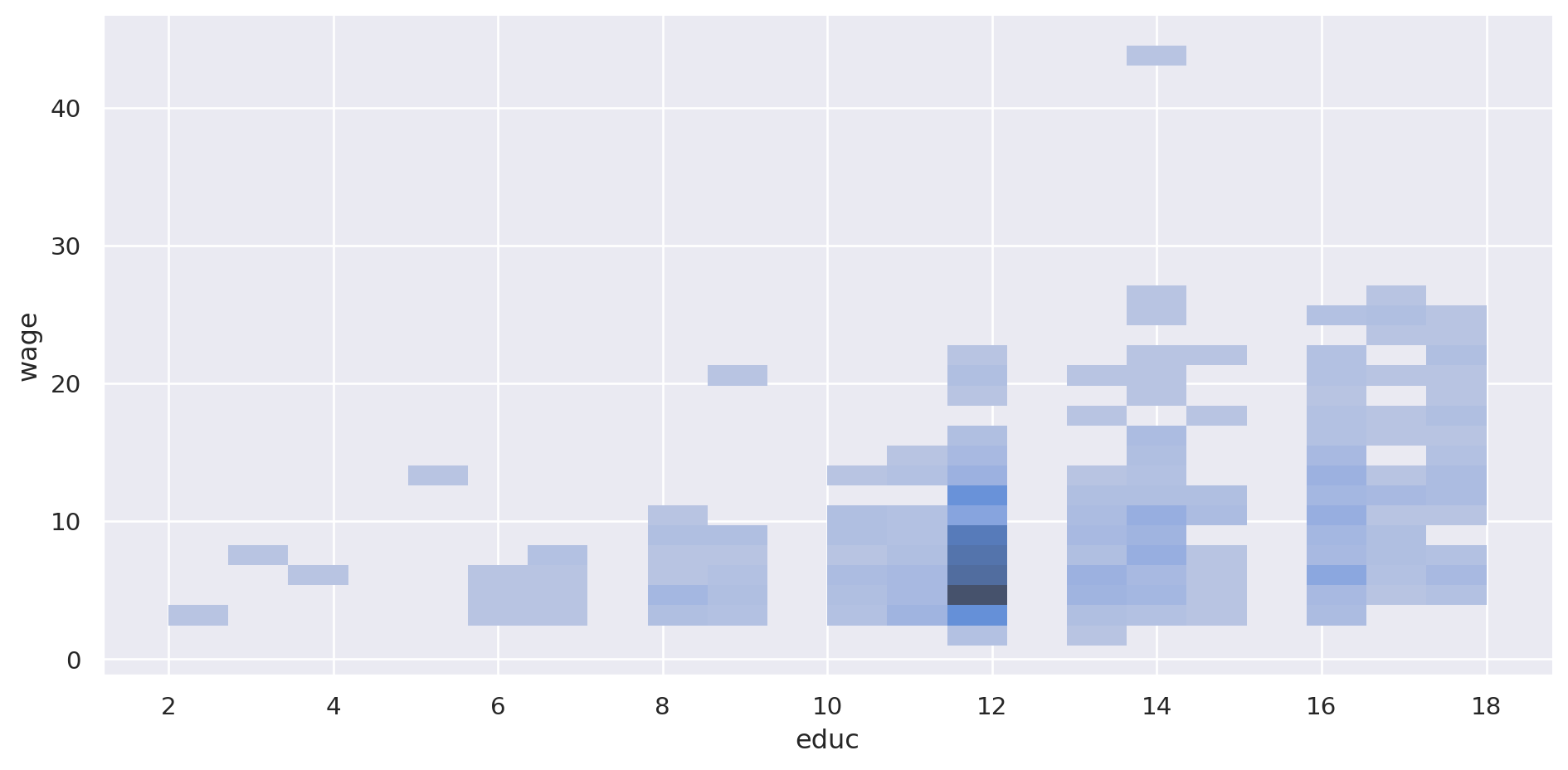
¿Y si queremos ver las combinaciones más numerosas?
= "wage" , x= "educ" , data= pop, kind= "hist" , aspect= 2 )
Un nivel educativo de 12 con sueldo inferior a 10 es común.
= 'skyblue' ).encode('wage:Q' , bin = alt.Bin(step= 1 )),'educ:Q' , bin = alt.Bin(step= 1 )),'count():Q' , scale= alt.Scale(scheme= 'greenblue' )),= 800 , height= 400 )
Diferenciando por más atributos
Si queremos ver la influencia sobre una clase, se puede usar el atributo hue:
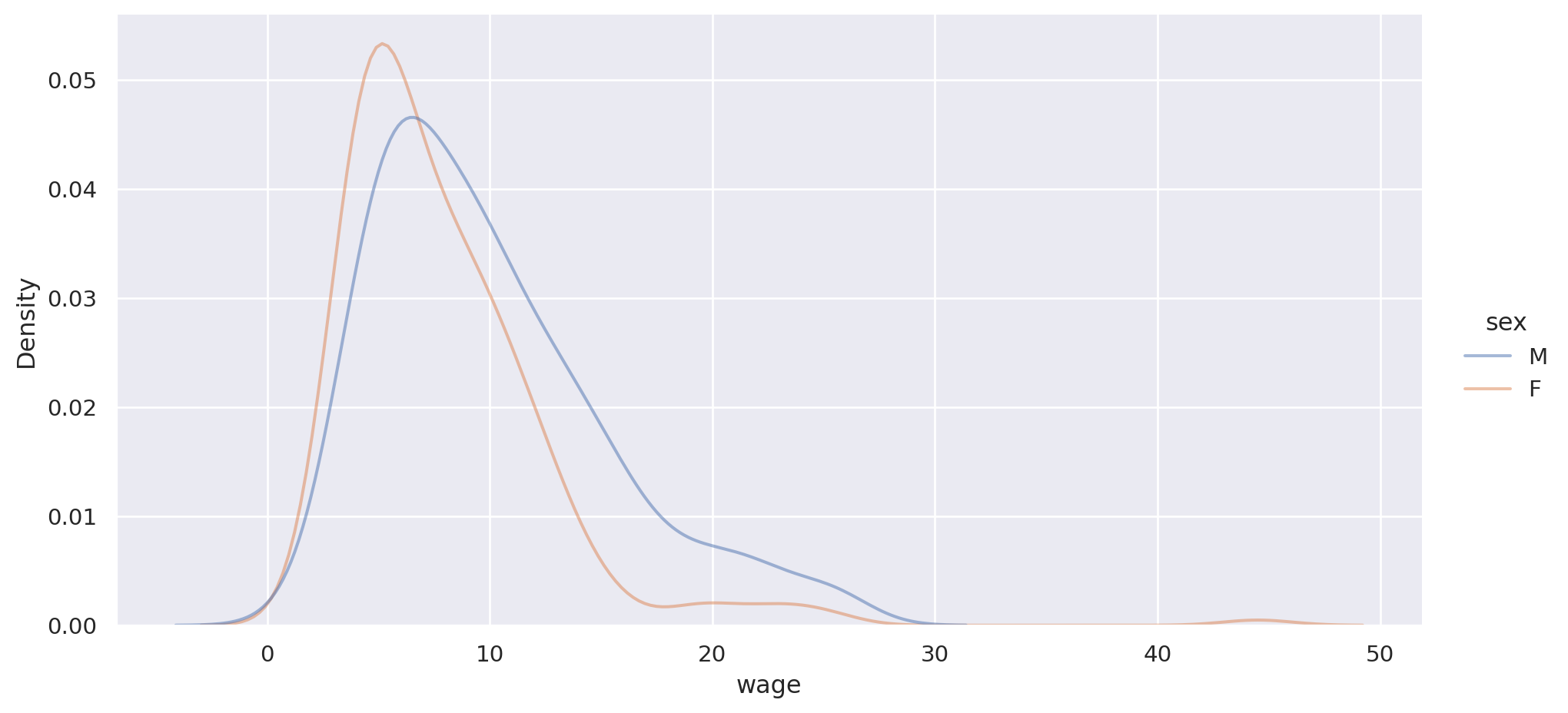
Ejemplo: Distribución considerando el sexo.
= "wage" , hue= "sex" , alpha= 0.5 , data= pop, kind= "kde" , aspect= 2 )
Parece diferente por sexo.
'wage:Q' ,bin = alt.Bin(step= 1 )),= 'count():Q' ,= alt.Color('sex:N' ,sort= alt.SortOrder('descending' )),= 800 , height= 400 )
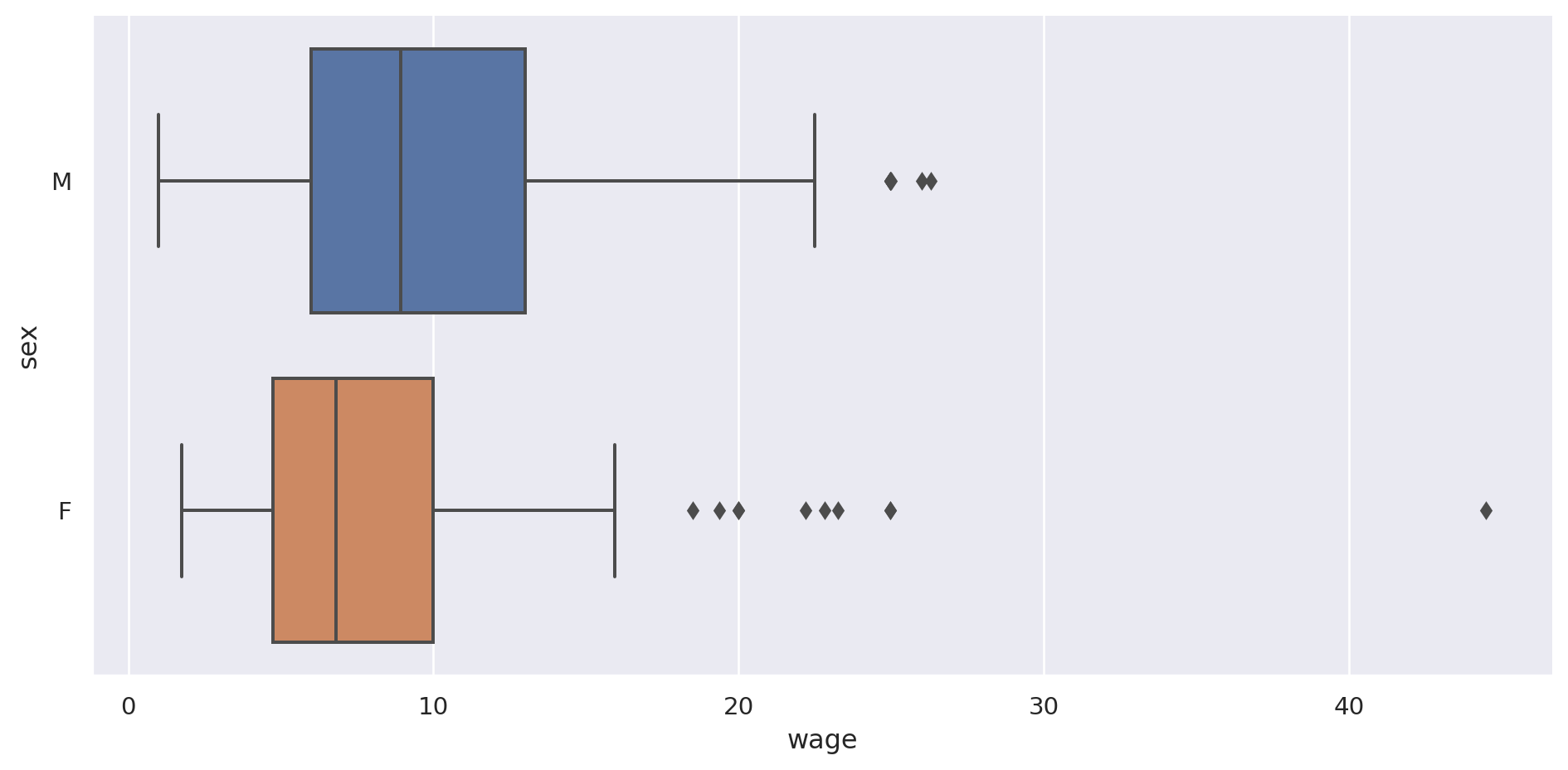
El box-plot lo visualiza mejor:
= "wage" , y= "sex" , data= pop, kind= "box" , aspect= 2 )
= 30 ,color= 'skyblue' ).encode(= 'wage:Q' ,= 'sex:N' ,= 'sex:N' = 800 , height= 400 )
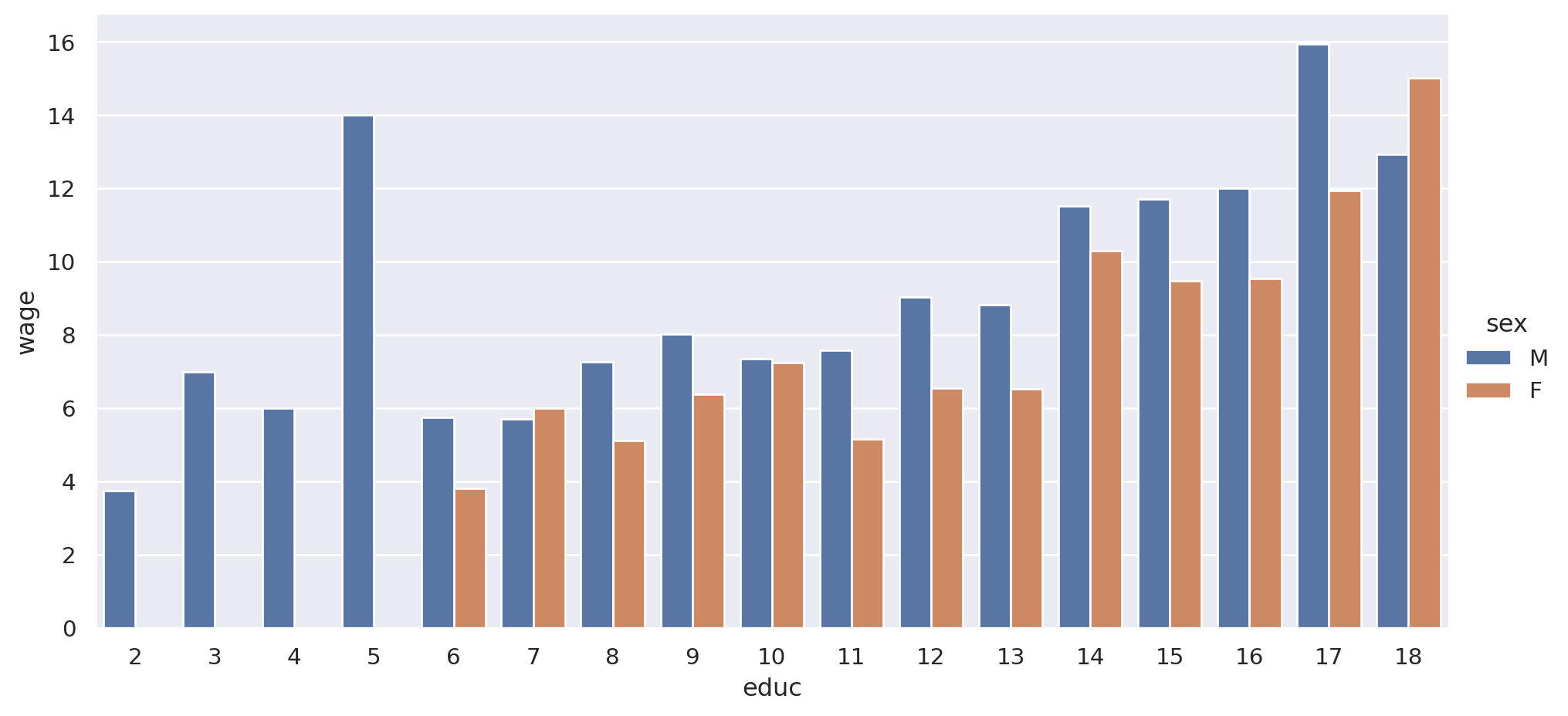
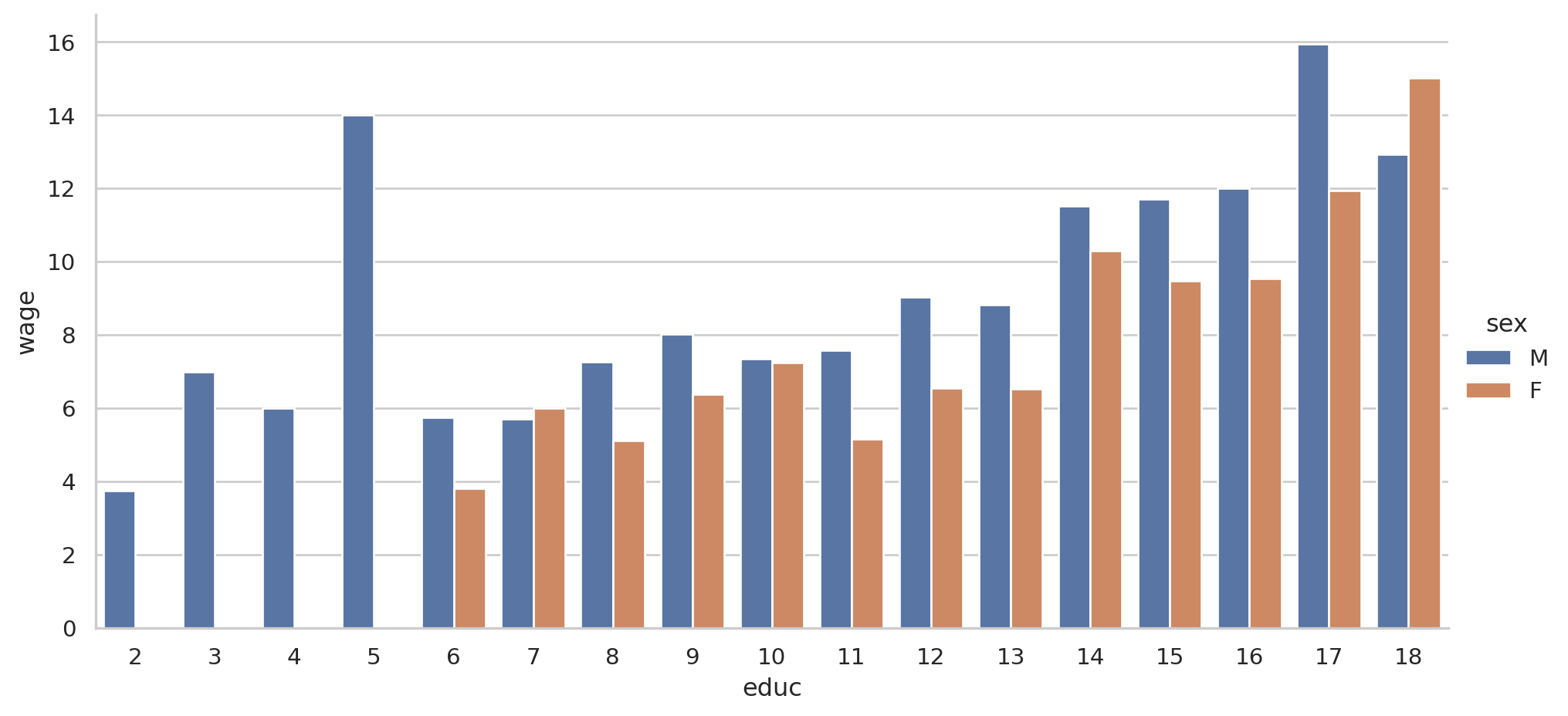
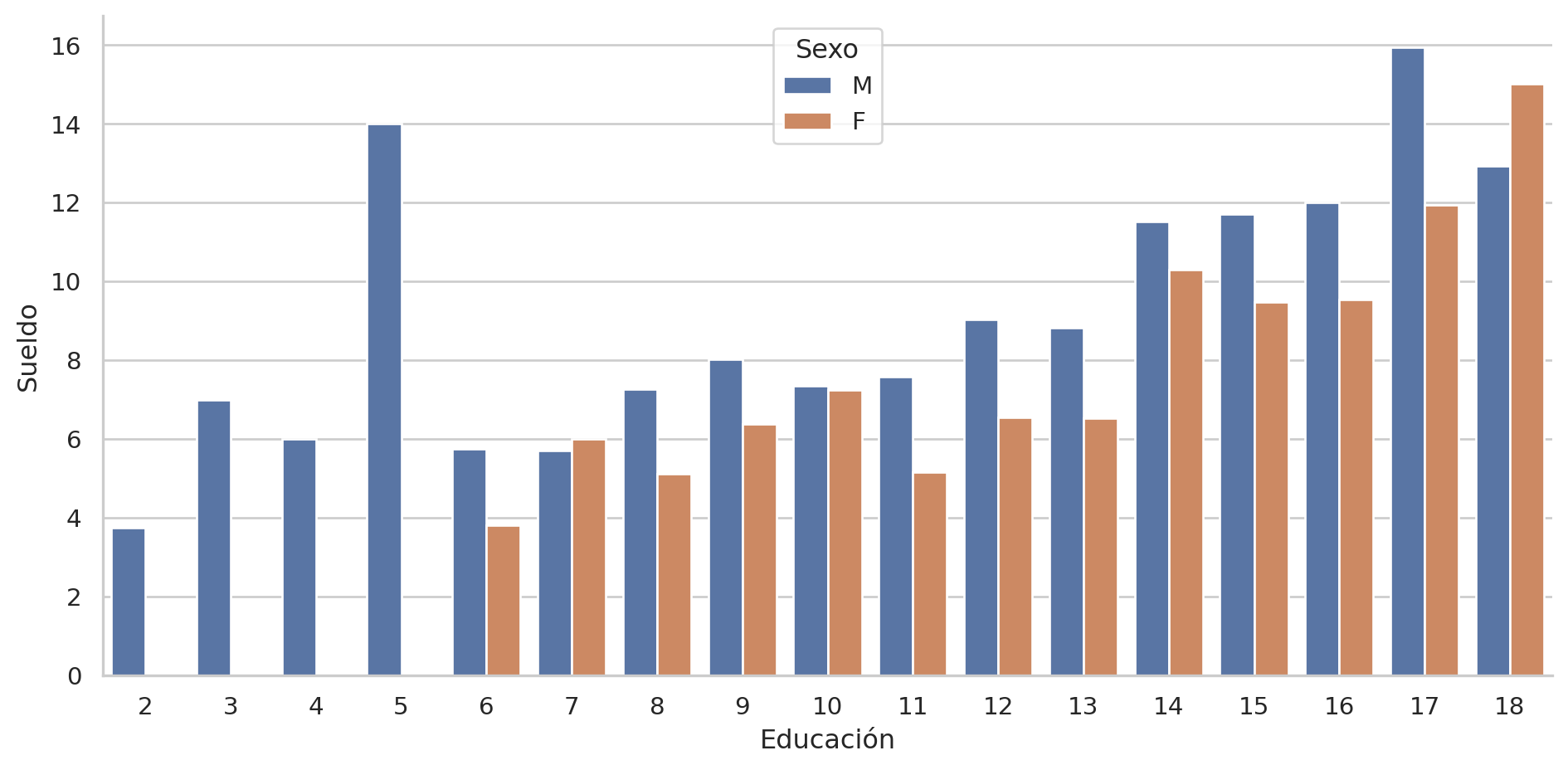
Analizamos con diagrama de barra:
= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 ); plt.show()
Se ve que el ingreso promedio es mayor para cada nivel formativo.
= 30 ,color= 'skyblue' ).encode(= 'educ:Q' ,= 'mean(wage):Q' ,= 'sex:N' ,= 'sex:N' = 50 , height= 400 )
Subfiguras por criterio
A menudo nos interesa visualizar ciertos datos de forma separada.
Se podría hacer haciendo selecciones usando pandas, pero la librería lo permite.
AVamos a usar el otro datasets , el de los pingüinos.
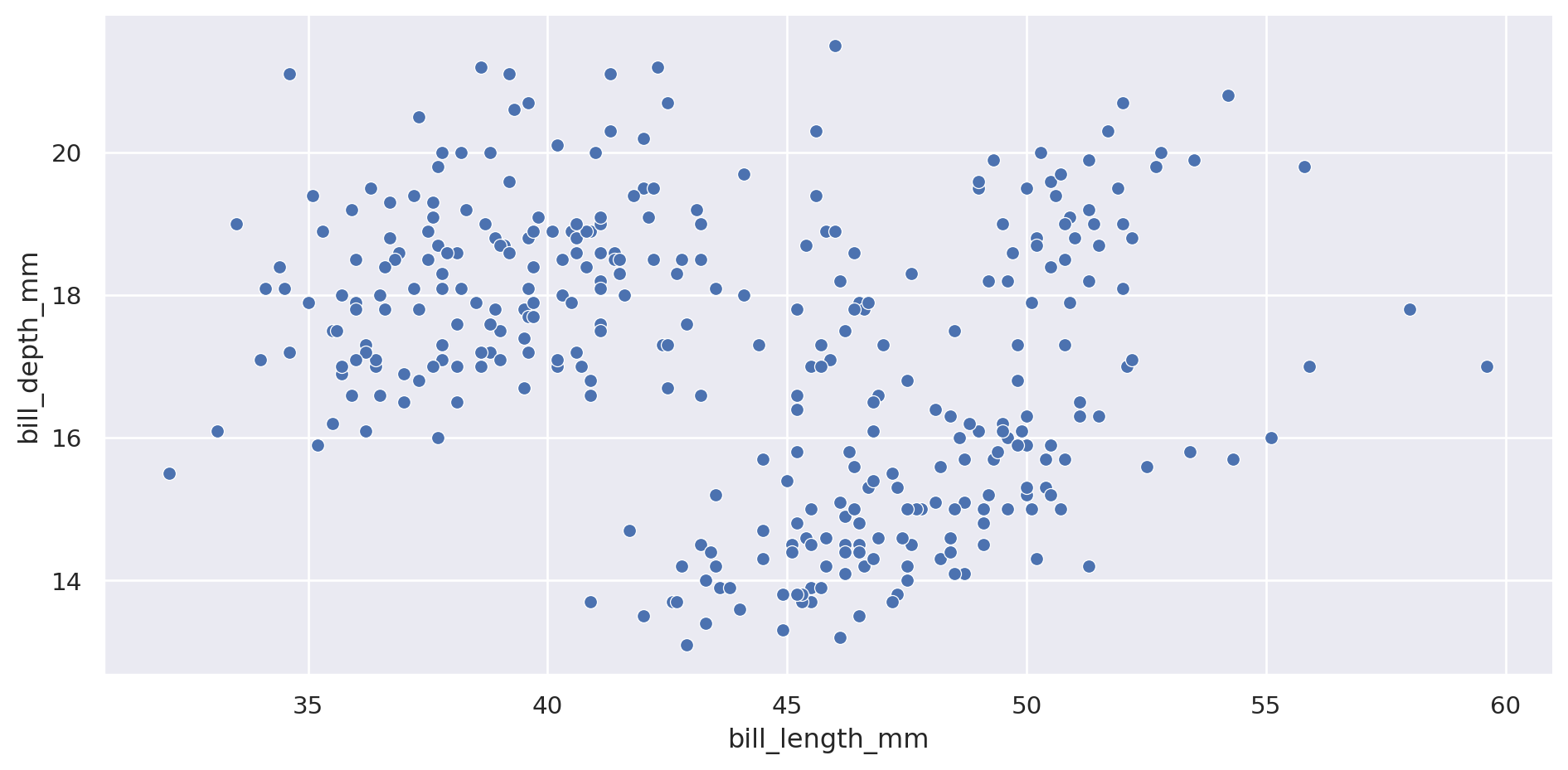
Primero vamos a mostrar para los tamaños la especie que es
= "bill_length_mm" , y= "bill_depth_mm" , data= penguins, aspect= 2 )
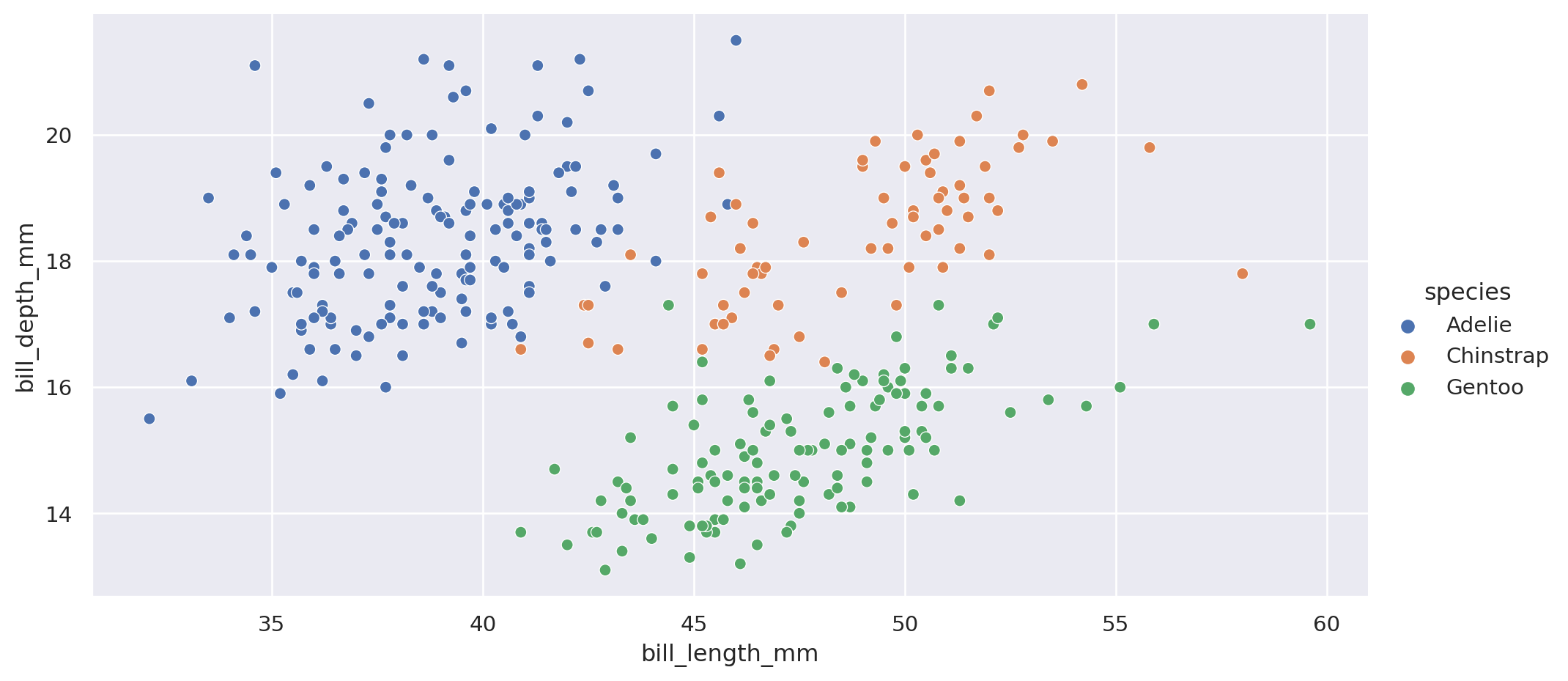
Vamos a visualizar las clases.
= "bill_length_mm" , y= "bill_depth_mm" , data= penguins,= "species" , aspect= 2 )
Tiene pinta de ser bastante separables, de todas formas vamos a analizar por islas.
= alt.Scale(zero= False )= alt.X('bill_length_mm:Q' ,scale= scale),= alt.Y('bill_depth_mm:Q' ,scale= scale),= 'species' = 800 ,height= 400 )
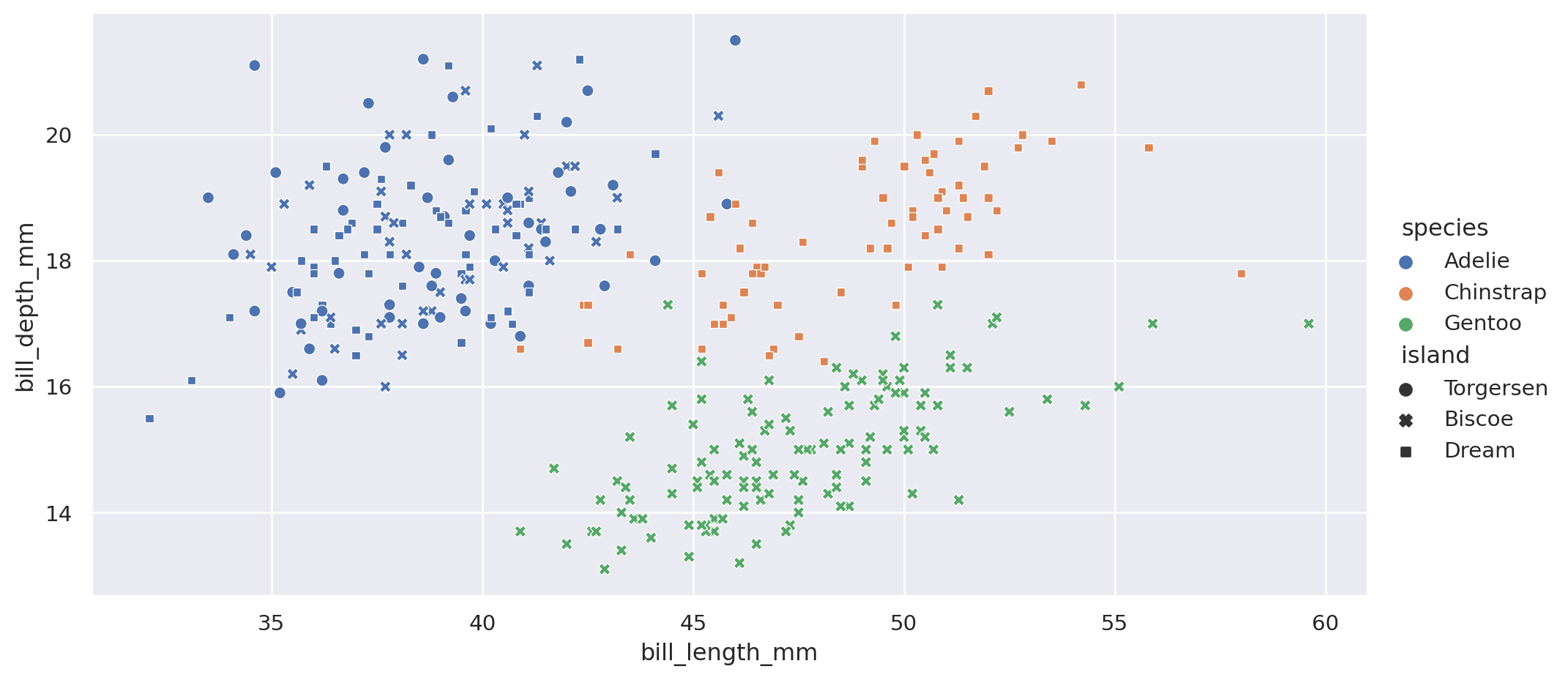
Podemos usar otros atributos, pero a veces no es claro:
= "bill_length_mm" , y= "bill_depth_mm" , data= penguins,= "species" , style= 'island' , aspect= 2 )
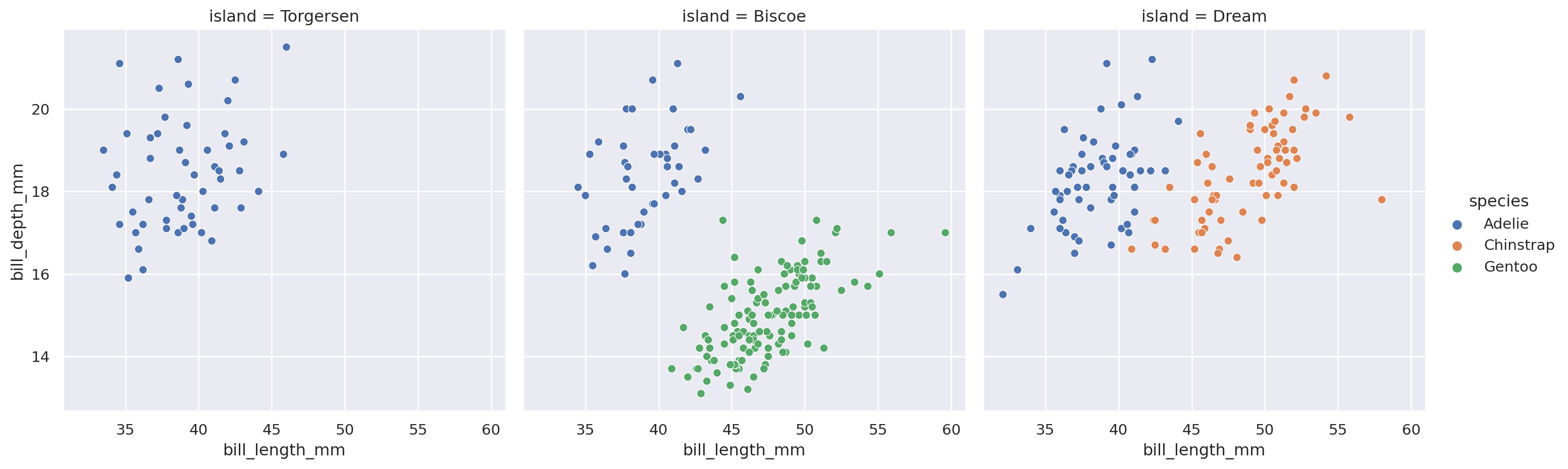
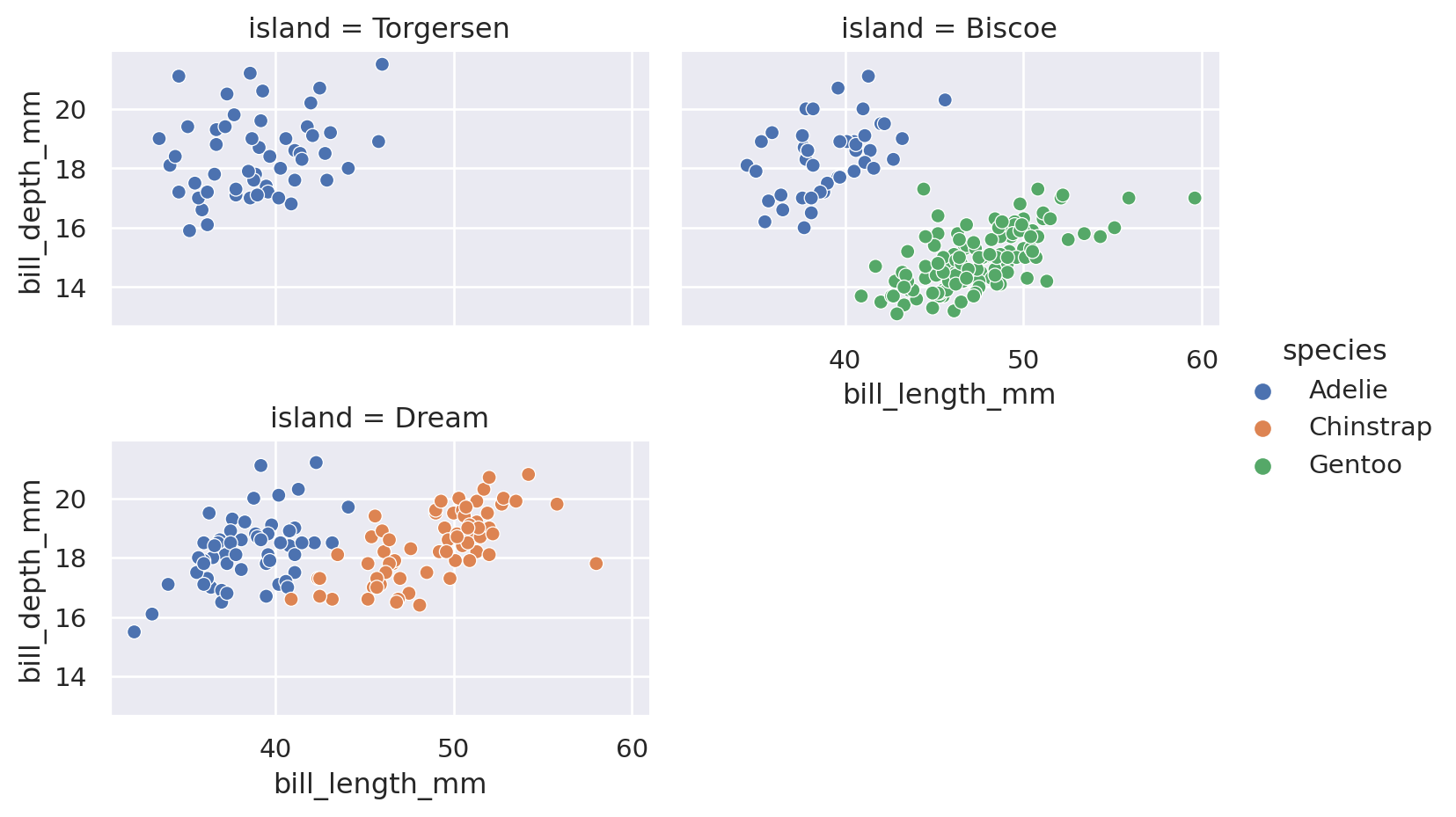
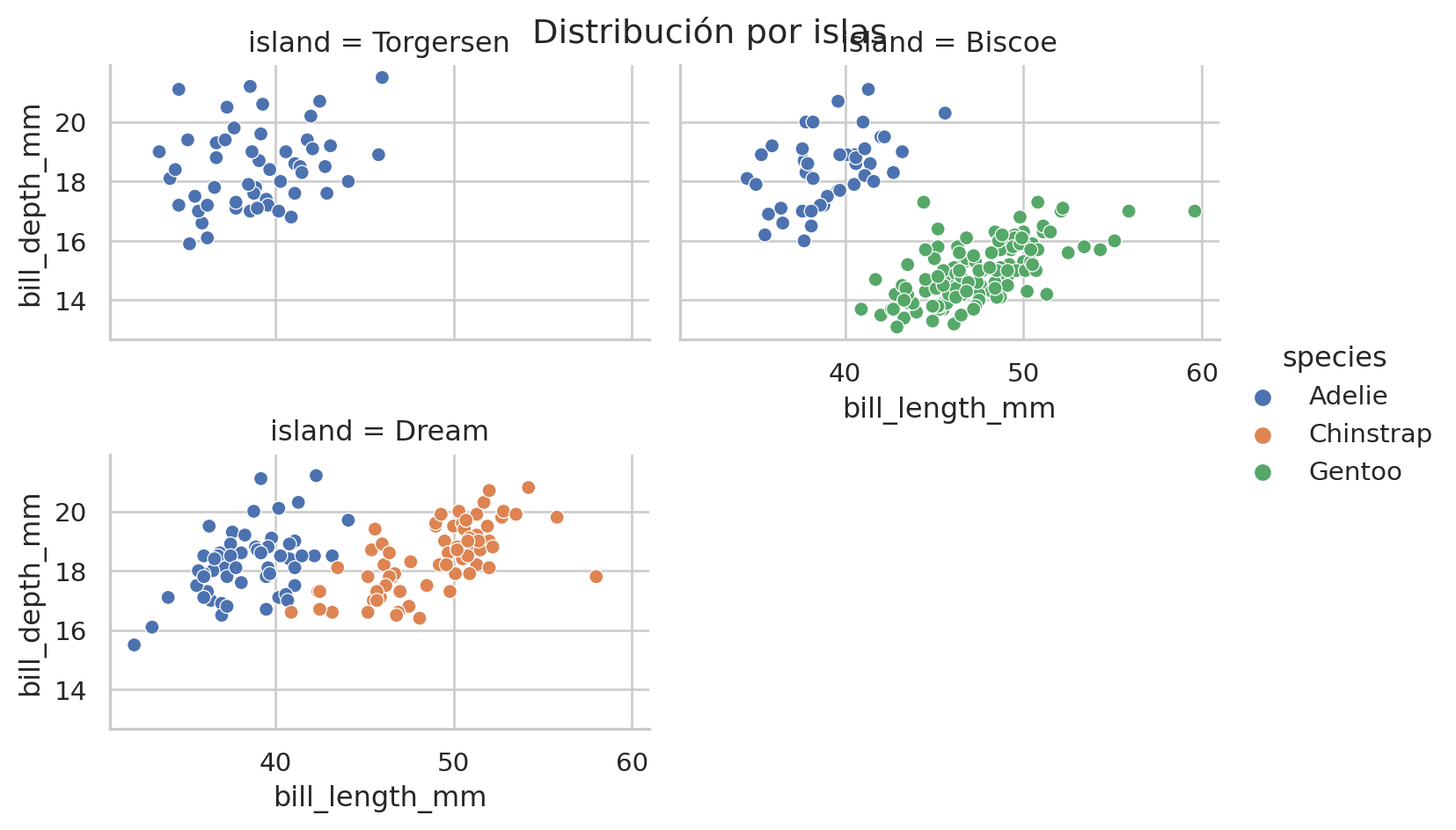
= "bill_length_mm" , y= "bill_depth_mm" , data= penguins,= "species" , col= "island" , aspect= 1 )
Se observa que el problema es aún más fácil, no en todas las islas están todas las especies.
Se puede limitar usando col_wrap y row_wrap para que no sea tan alargado.
# setting the dimensions of the plot = sns.relplot(x= "bill_length_mm" , y= "bill_depth_mm" , data= penguins,= "species" , col= "island" , col_wrap= 2 ,= 2.5 , aspect= 1.5 )
Desde Altair también es fácil.
= 'bill_length_mm:Q' ,= 'bill_depth_mm:Q' ,= 'species:N' ,= 'island:N' = 250 , height= 400 )
Estilo (theme)
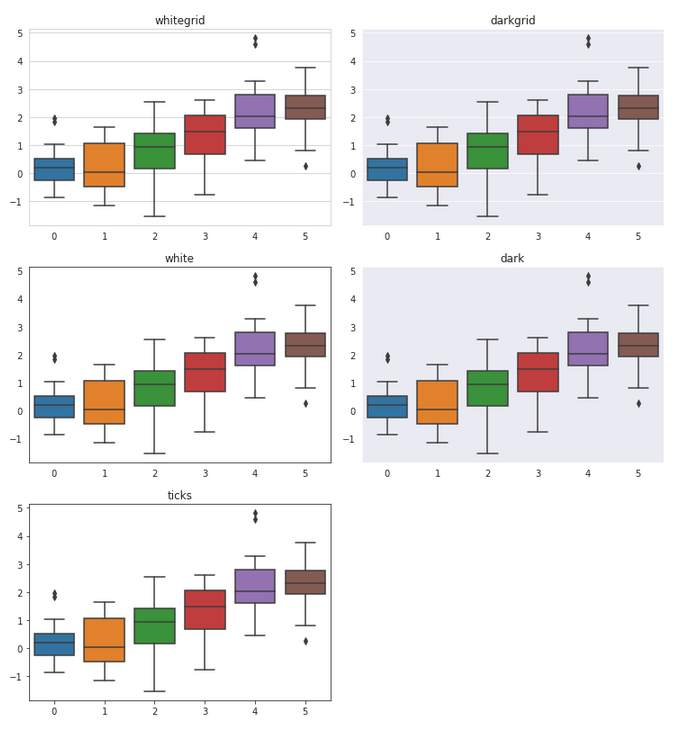
Se puede visualizar los themes:
darkgrid: Formato por defecto (como ggplot2).
dark: Sin líneas horizontales.
whitegrid: Blanco con líneas.
white: Blanco sin líneas.
ticks: Como white pero con ticks en los ejes.
= "whitegrid" )= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 )
Renombrar los ejes y/o title
Las funciones devuelven un objeto al que se puede definir los elementos.
Definir atributos, por medio de set:
xlabel: Etiqueta eje x.
ylabel: Etiqueta eje y.
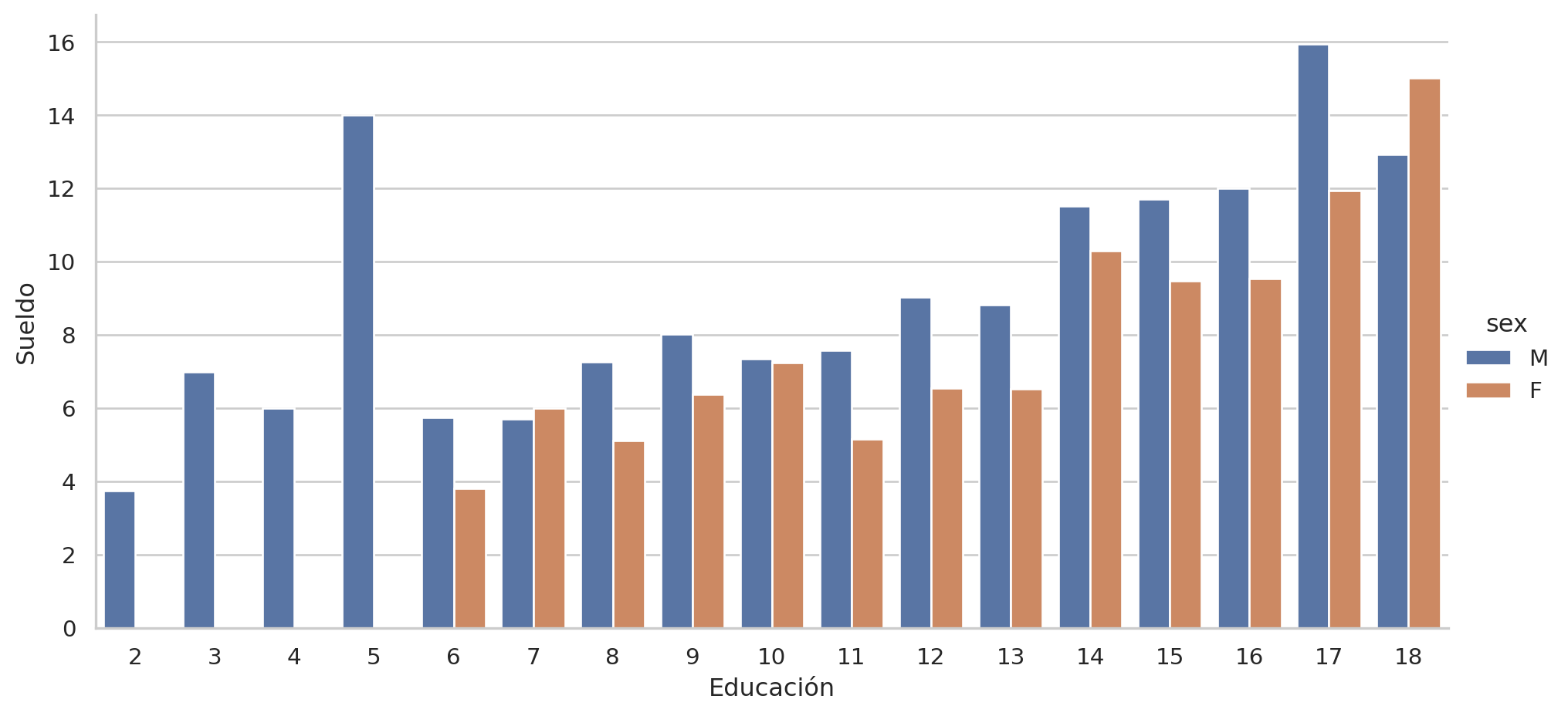
= sns.catplot(y= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 )set (xlabel= "Educación" , ylabel= "Sueldo" )
Falta la leyenda, se cambia con plt.legend:
= sns.catplot(y= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 , legend= False )set (xlabel= "Educación" , ylabel= "Sueldo" )= "Sexo" )
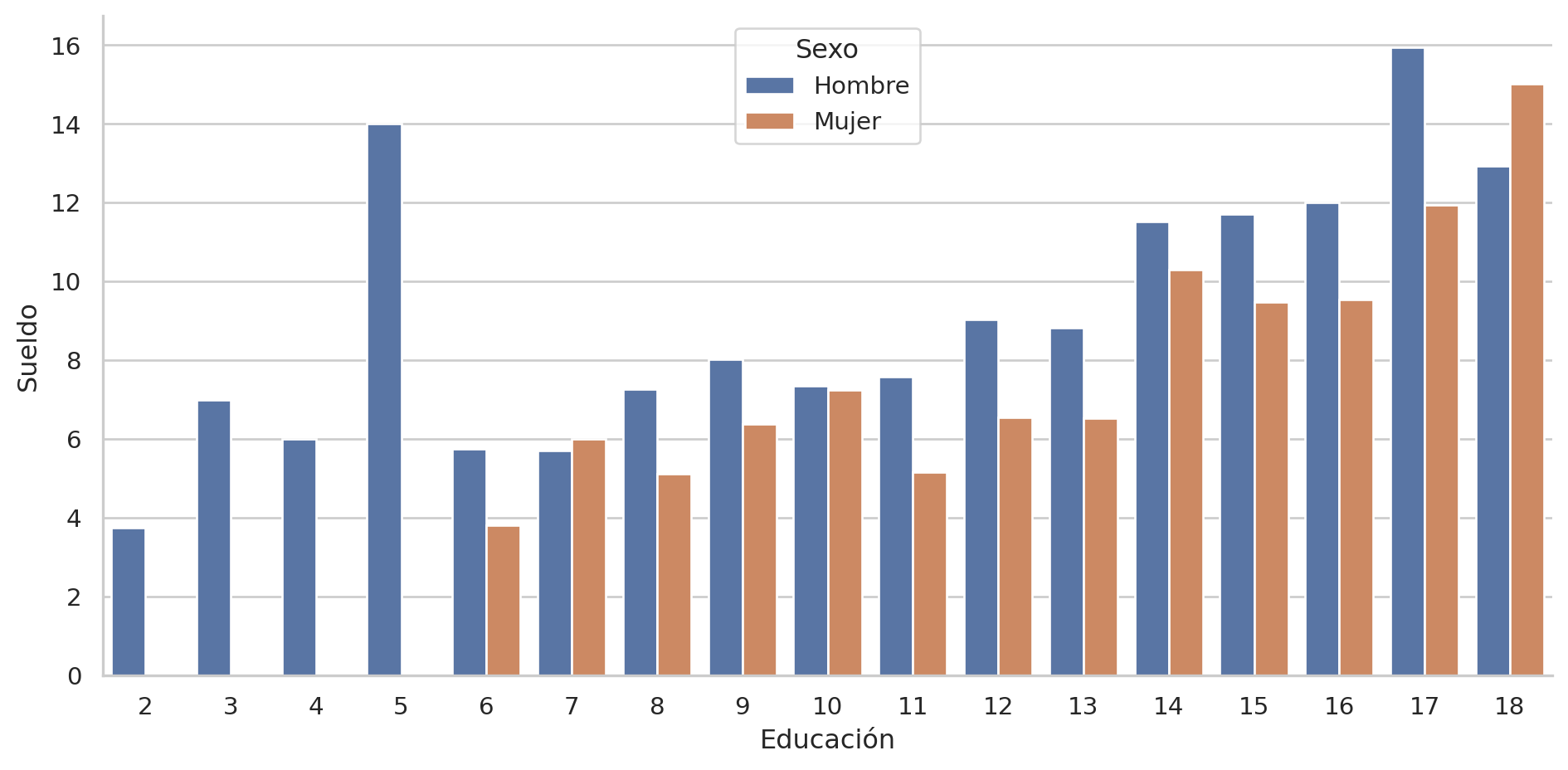
Re-etiquetar:
= sns.catplot(y= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 , legend= False )set (xlabel= "Educación" , ylabel= "Sueldo" )= "Sexo" , labels= ["Hombre" , "Mujer" ])
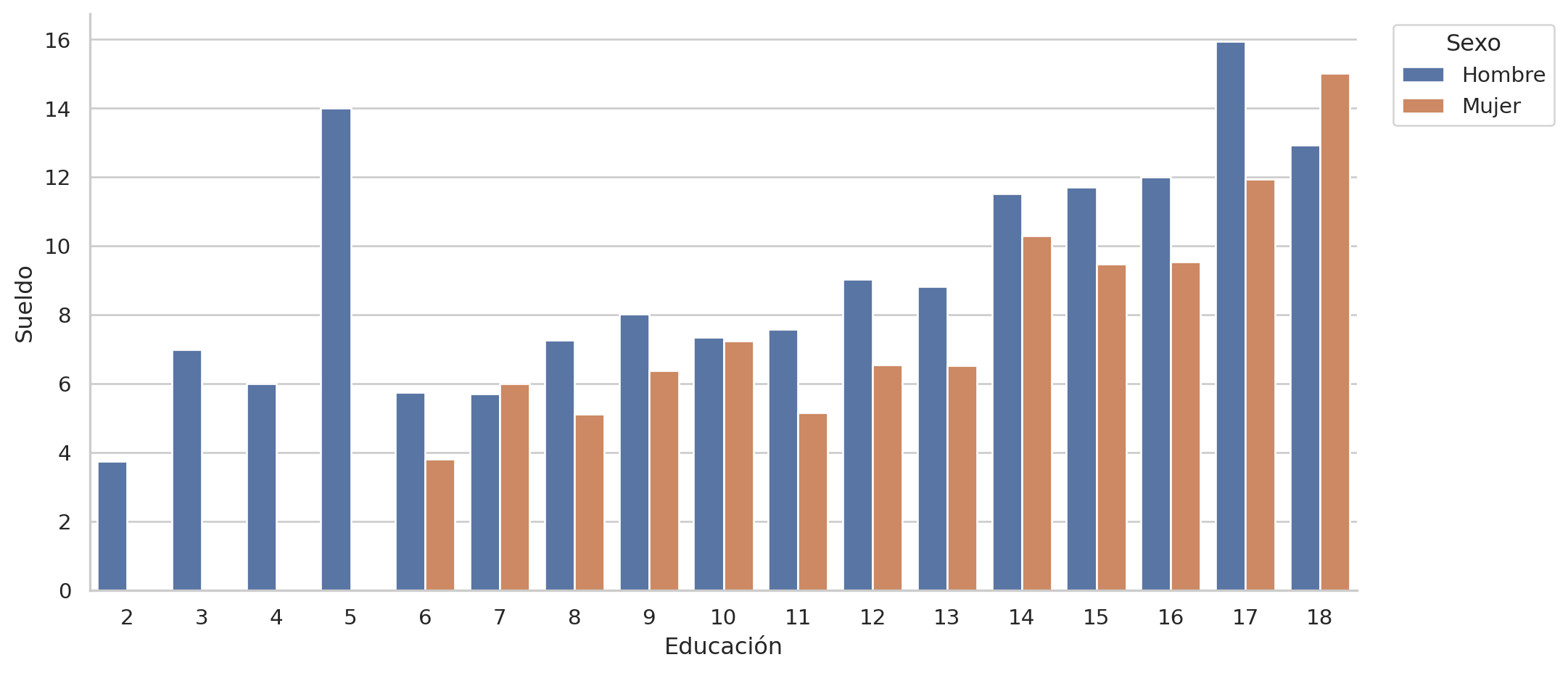
Localización
= sns.catplot(y= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 , legend= False )set (xlabel= "Educación" , ylabel= "Sueldo" )= "Sexo" , labels= ["Hombre" , "Mujer" ],= (1.02 ,1 ))
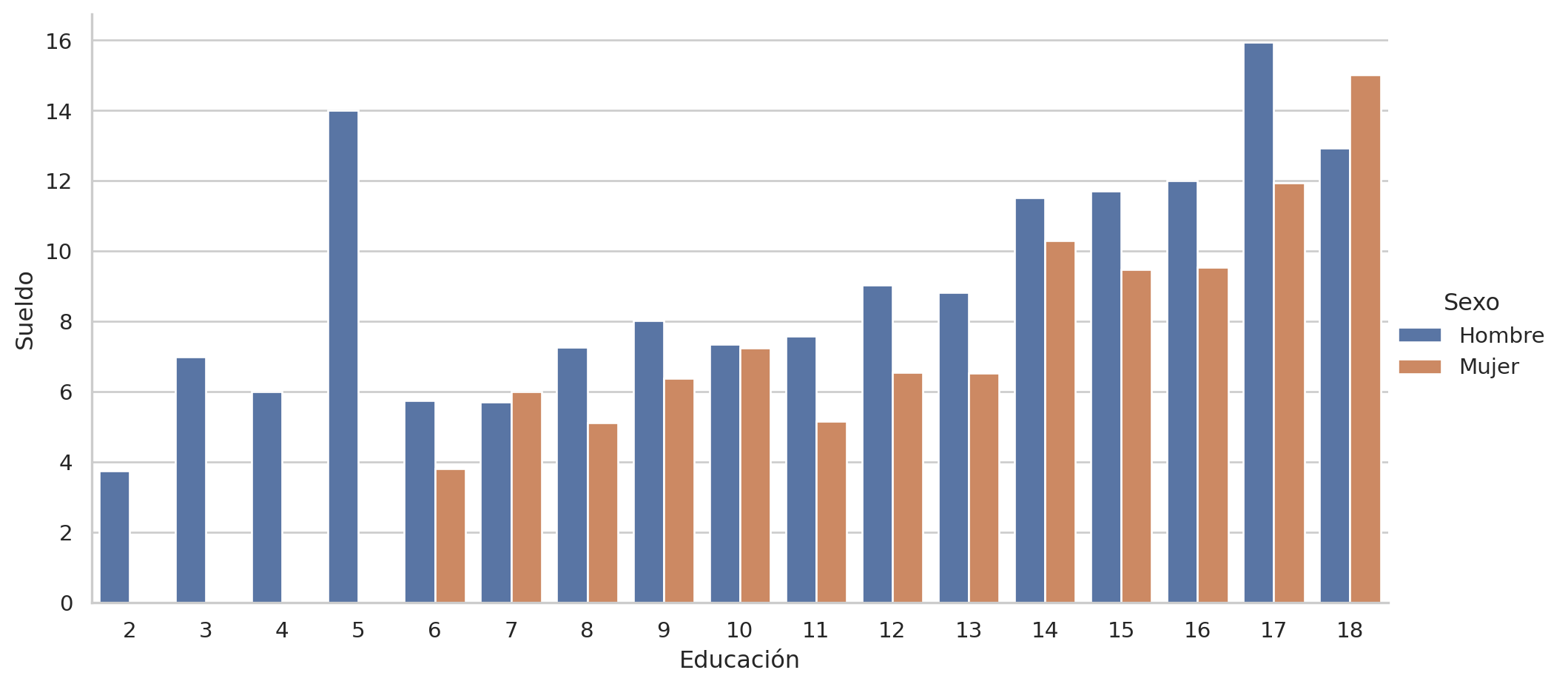
Usando move_legend
= sns.catplot(y= "wage" , x= "educ" , data= pop, hue= "sex" , kind= "bar" ,= None , aspect= 2 )set (xlabel= "Educación" , ylabel= "Sueldo" )"upper left" , bbox_to_anchor= (0.92 , 0.6 ),= "Sexo" , labels= ["Hombre" , "Mujer" ])
Dado que se pueden crear subfiguras para el título es bueno usar ‘XX.figure.suptitle’.
= sns.relplot(x= "bill_length_mm" , y= "bill_depth_mm" , data= penguins,= "species" , col= "island" , col_wrap= 2 ,= 2.5 , aspect= 1.5 )"Distribución por islas" )
Personalizando en Altair
Personalizando una gráfica en Altair es más intuitivo, al ser más explícito.
= alt.Scale(zero= False )= alt.X('bill_length_mm:Q' ,scale= scale),= alt.Y('bill_depth_mm:Q' ,scale= scale),= 'species' = 800 ,height= 400 )
= alt.Scale(zero= False )= alt.X('bill_length_mm:Q' ,scale= scale, title= "Longitud (mm)" ),= alt.Y('bill_depth_mm:Q' ,scale= scale, title= "Profundidad (mm)" ),= alt.Color('species' , title= "Especie" )= 800 ,height= 400 )
Altair es interactivo:
= alt.Scale(zero= False )= alt.X('bill_length_mm:Q' ,scale= scale, title= "Longitud (mm)" ),= alt.Y('bill_depth_mm:Q' ,scale= scale, title= "Profundidad (mm)" ),= alt.Color('species' , title= "Especie" )= 800 ,height= 400 ).interactive()
Altair también permite asociar diagramas:
Altair también permite asociar diagramas:
= alt.Scale(zero= False )= alt.selection_interval()= alt.Chart(penguins).mark_point().encode(= alt.X('bill_length_mm:Q' ,scale= scale, title= "Longitud (mm)" ),= alt.Y('bill_depth_mm:Q' ,scale= scale, title= "Profundidad (mm)" ),= alt.Color('species' , title= "Especie" )= 800 ,height= 400 ).add_selection(brush)= alt.Chart(penguins).mark_bar().encode(= 'species:N' ,= 'species:N' ,= 'count(species):O'
Ejercicios de visualización
Vamos a usar un datasets tips existen datos de consumo en un restaurante. Indica para cada consumición el precio total_bill , la propina y datos del cliente (sex , smoker ), el día de la semana, y la hora (Lunch , Dinner ).
= sns.load_dataset("tips" )
Ejercicios de visualización
Visualizar la distribución de propinas en función de la factura total.
Igual pero destacando por la hora.
Mostrar la frecuencia distinguiendo por sexo del cliente.
Mostrar la frecuencia distinguiendo por sexo en función de la hora.
Crear el diagrama (lmplot) de la relación propina y factura en función de la hora.
Mostrar en un box-plot la factura en función de la hora.
Igual que el anterior pero distinguiendo por el sexo.
Ejercicios de visualización
Mostrar un kde de la factura distinguiendo por sexo y separando por la hora.
Calcular el ratio y visualizar las facturas y el ratio separando en base a la hora.
¿Ser fumador influye?
¿La hora influye en la factura? ¿Y en el ratio? Visualiza para justificarlo.
Visualizar la distribución del ratio para cada hora.
Crear un diagrama de barras para comparar el ratio promedio por cada sexo para cada hora. ¿La diferencia es relevante?
Crear un diagrama de barras para comparar el ratio promedio por cada sexo separando si es fumador. ¿La diferencia es relevante?
¿Está bien balanceados los experimentos respecto a la hora, el sexo, o si son fumador?
Mejora y “traduce” uno de las gráficas complejas anteriores.